
Introduction – Claude 3.7 vs Grok 3
Recent experimentation with Claude 3.7 vs Grok 3 models indicates substantial performance improvements compared to their predecessors. Grok 3 reportedly represents the first publicly available model trained with computational resources exceeding GPT-4 by an order of magnitude, while Claude 3.7 introduces enhanced reasoning and coding capabilities. These developments provide insights into the projected trajectory of artificial intelligence advancement.
Performance Assessment
Initial evaluation suggests these newer models demonstrate marked improvements in handling complex tasks, mathematical problems, and code generation. The performance differential appears particularly notable in Claude’s code generation capabilities, which reportedly allows non-technical users to develop functional programs through natural language interaction.
For instance, when presented with a proposal for an AI educational tool and requested to “display the proposed system architecture in 3D, make it interactive,” Claude 3.7 generated a functional interactive visualization without errors. The significant observation was not the graphical output but rather the model’s decision to implement a step-by-step demonstration explaining the concepts without explicit instructions to do so. This behavior suggests improved anticipation of user requirements.
In another test case, providing Claude with simple instructions to create “an interactive time machine artifact” with “more graphics” resulted in a functional interactive experience featuring pixel graphics generated entirely through code without visual feedback.
While these systems demonstrate limitations and errors, their performance trajectory appears to be rapidly advancing.
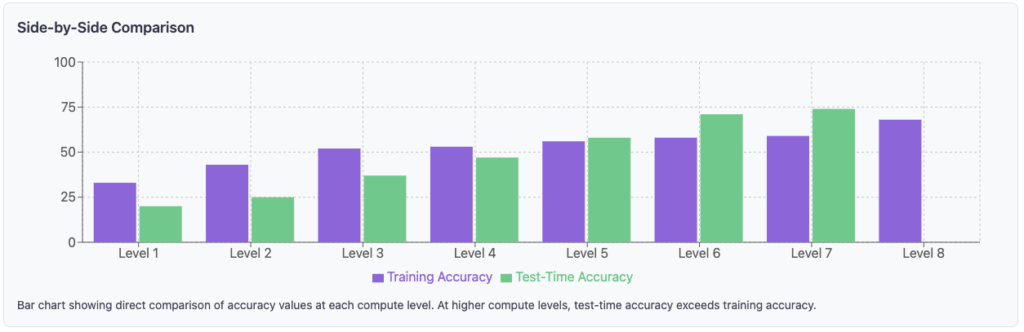
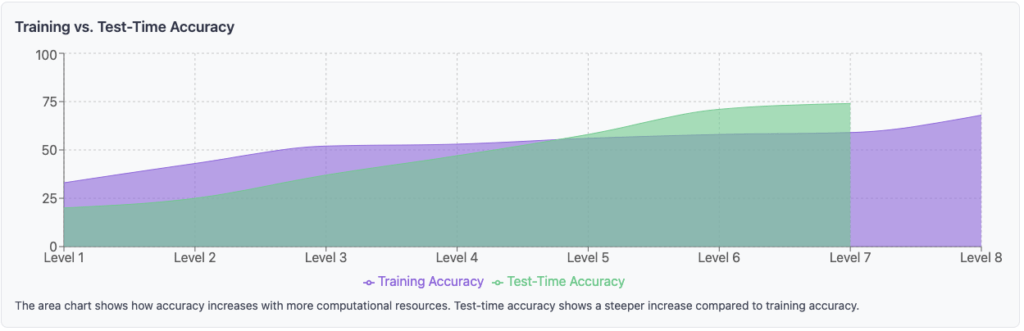
Economic Implications
These parallel developments appear to be simultaneously improving model capabilities while reducing operational costs. For instance, when GPT-4 was initially released, usage reportedly cost approximately $50 per million tokens (roughly equivalent to one million words). Current models like Gemini 1.5 Flash, which demonstrate superior capabilities to the original GPT-4, operate at approximately $0.12 per million tokens.
Professional performance benchmarks provide context: on the Graduate-Level Google-Proof Q&A test (GPQA), which consists of challenging multiple-choice problems designed to assess advanced knowledge, PhDs with internet access reportedly achieve 34% accuracy outside their specialization and 81% within their specialty. The latest models approach or exceed these benchmarks at continuously decreasing operational costs.
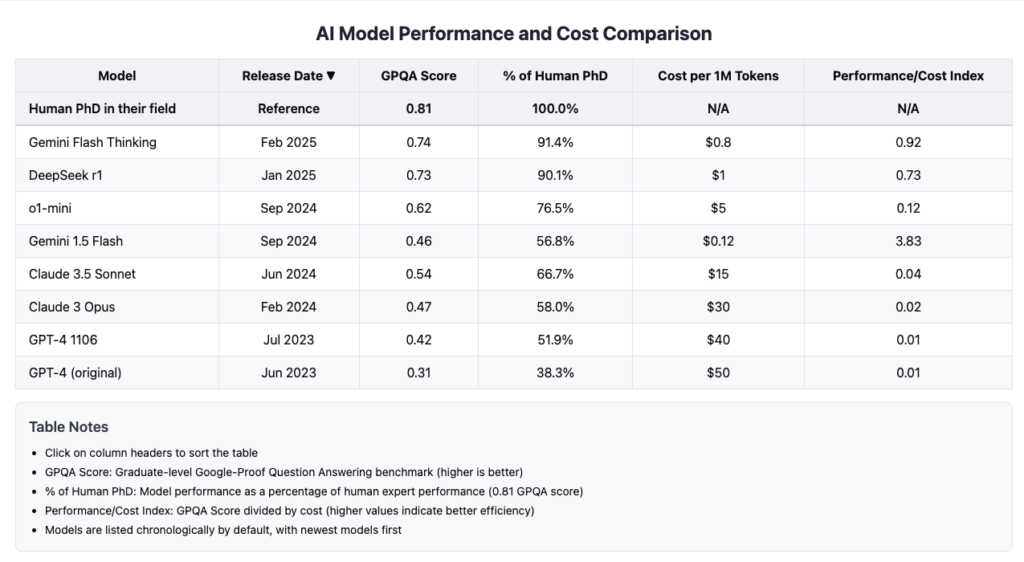
Strategic Considerations
Much of the organizational focus on artificial intelligence, particularly in corporate environments, has centered on what might be termed an “automation mindset”—viewing AI primarily as a tool for optimizing existing workflows. This perspective was appropriate for earlier models but requires reconsideration given recent capabilities.
As models improve through increased scale, reasoning capabilities, and internet access, they demonstrate reduced hallucination rates (though errors persist) and higher-order analytical capabilities. For example, when presented with a 24-page academic paper outlining a novel approach to AI-based educational games, alongside unrelated instruction manuals, Claude produced a high-quality consumer guide based on the academic content. This task required abstracting concepts from the paper, analyzing patterns from instruction manuals, and synthesizing original content—work estimated to require approximately one week of doctoral-level effort but completed in seconds.
Organizational leadership may need to reassess AI capabilities and potential applications. Rather than assuming these tools are limited to lower-complexity tasks, consideration should be given to their potential as analytical partners. Current models demonstrate capacity for complex analysis, creative work, and research-level problem-solving with increasing sophistication. While not consistently outperforming human experts across all domains, their capabilities warrant serious evaluation.
This evolution suggests three primary strategic implications:
- The focus should shift from task automation to capability augmentation, with leaders asking, “What new capabilities can we unlock?” rather than “What tasks can we automate?”
- Given rapid capability improvement and cost efficiency, static implementation strategies will quickly become obsolete. Organizations require adaptable approaches that evolve with advancing models.
- Traditional evaluation metrics focused on time or cost reduction may fail to capture transformative impacts related to insight generation, information synthesis, and novel problem-solving approaches. An excessive focus on concrete key performance indicators may limit exploratory potential and encourage viewing AI primarily as a labor replacement rather than considering human-AI collaboration models.
Practical Assessment
Despite these strategic considerations, hands-on evaluation remains essential. The latest models demonstrate improved engagement capabilities, including clarifying questions and guiding user thinking. Direct experimentation provides the most reliable assessment of capabilities.
Claude 3.7 is available to paying customers and features functionality to execute generated code. According to company statements, it does not train on user-uploaded data. Grok 3 is available without charge and offers additional features, including research capabilities, although it has reportedly less intuitive coding interfaces compared to Claude 3.7, based on initial testing. It should be noted that Grok does train on user data by default, though this can be disabled for paying customers.
Regardless of platform selection, practical testing is recommended. Potential approaches include requesting code generation without specialized knowledge, document analysis with infographic summarization, or image commentary. For professional applications, models can be utilized for ideation, analysis of industry publications, or the creation of financial visualizations for new concepts. Results will likely demonstrate both impressive capabilities and persistent limitations.
While current models maintain significant constraints, comparative analysis between generations demonstrates that both scaling laws continue to apply. This suggests continued capability improvement as computational resources increase. As long as these relationships hold, artificial intelligence systems may continue to advance in capability.










