So verstehen und interpretieren Sie Java-Stack-Traces zum Debuggen von Problemen
Java-Stack-Traces sind ein wertvolles Tool zum Debuggen von Problemen in Ihrer Java-Anwendung. Sie liefern einen Bericht über die Reihenfolge der Methodenaufrufe, die zu einem Fehler geführt haben, beginnend mit der Methode, die den Fehler verursacht hat, und zurück zum ersten Methodenaufruf. In diesem Artikel wird erläutert, wie Sie Java-Stack-Traces verstehen und interpretieren, um Sie bei der Fehlerbehebung und Behebung von Problemen in Ihrer Anwendung zu unterstützen.
Was ist ein Java Stack Trace?
Der Stack ist ein wichtiger Bestandteil der Java-Laufzeitumgebung. Er dient zum Speichern lokaler Variablen und Methodenaufrufe für jeden Thread in einer Anwendung. Wenn Sie verstehen, wie der Stack funktioniert und wie ein Stack-Trace zu interpretieren ist, können Sie häufig Probleme in Ihrer Java-Anwendung lokalisieren.
Ein Stack-Trace besteht aus einer Liste von Stack-Frames. Die Sammlung dieser Frames (die den Stack-Trace bilden) stellt einen Zeitpunkt während der Ausführung einer Anwendung dar. Ein Stapelrahmen enthält Informationen zu einer Methode oder Funktion, die Ihre Anwendung aufgerufen hat.
Ein Java-Stack-Trace ist eine Momentaufnahme des aktuellen Status des Stapels für einen Thread in einer Java-Anwendung . Es kann verwendet werden, um die Ursache eines Fehlers oder eines anderen Problems in der Anwendung zu identifizieren. Immer wenn ein Fehler ausgelöst wird, besteht der Stapel aus einer Sammlung von Funktionsaufrufen, die zu dem Aufruf führen, der den Fehler verursacht hat. Dies basiert auf dem LIFO-Verhalten (Last In, First Out) des Stapels.
Die Verwendung eines Debuggers kann hilfreich sein, um den Stack ( der in FusionReactor integriert ist ) zu verstehen. Es kann auch hilfreich sein, Protokollnachrichten zu schreiben, um den Status des Stapels an verschiedenen Stellen in der Anwendung zu verfolgen. FusionReactor erfasst automatisch den vollständigen Stack-Trace zusammen mit Verweisen auf den zugrunde liegenden Code und den Variablenbereichskontext für jede Variable auf dem Stack.
Welche Fehler können über einen Stacktrace identifiziert werden?
Dies kann Ihnen dabei helfen, Probleme zu identifizieren wie:
- Stapelüberläufe : Ein Stapelüberlauf tritt auf, wenn auf dem Stapel nicht mehr genügend Speicherplatz vorhanden ist und keine neuen Variablen oder Methodenaufrufe gespeichert werden können. Dies kann durch eine unendliche Rekursion oder eine große Anzahl verschachtelter Methodenaufrufe verursacht werden.
- Falsch zugewiesene Variablen : Wenn Variablen falsch auf dem Stapel zugewiesen werden, kann dies zu Problemen wie Nullzeigern oder falschen Werten führen.
- Falsch implementierte Methodenaufrufe : Wenn Methodenaufrufe falsch implementiert werden, kann dies zu Problemen wie falschen Rückgabewerten oder unerwartetem Verhalten führen.
Wenn Sie den Stack und seine Funktionsweise verstehen, können Sie häufig Probleme in Ihrer Java-Anwendung lokalisieren und Maßnahmen zu deren Lösung ergreifen.
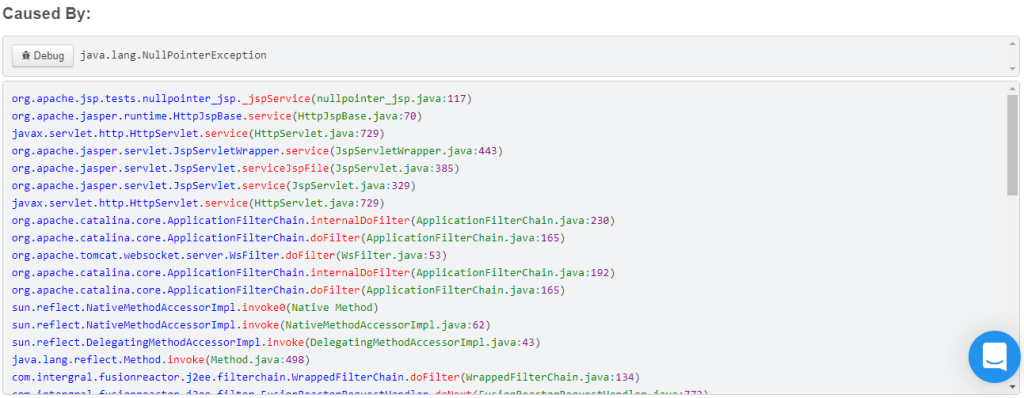
Ein typischer Stacktrace
Der Screenshot unten zeigt, wie ein Stack-Trace aussieht, wie er in FusionReactor gerendert wird. Klassen und Methoden sind anklickbar und führen dazu, dass eine Klasse oder Methode automatisch dekompiliert wird, wenn Sie die Erlaubnis dazu erteilt haben.
So interpretieren und verstehen Sie einen Stack-Trace
Das Debuggen von Problemen in einer Java-Anwendung erfordert häufig die Analyse des Stack-Trace einer Ausnahme oder eines Fehlers. Ein Stack-Trace ist eine Liste von Methodenaufrufen, die die Reihenfolge der ausgeführten Methoden anzeigt. Die Aufrufe führen bis zu dem Punkt, an dem die Ausnahme oder der Fehler aufgetreten ist.
Um einen Stack-Trace zu interpretieren und zu verstehen, befolgen Sie einfach diese Schritte:
- Identifizieren Sie die aufgetretene Ausnahme oder den aufgetretenen Fehler : Der Stack-Trace beginnt normalerweise mit einer Zeile, die den Typ der ausgelösten Ausnahme oder des Fehlers angibt, zusammen mit einer kurzen Beschreibung des Problems. Beispielsweise könnte eine Fehlermeldung „Nicht genügend Speicher“ auf ein Problem mit der Speicherzuweisung hinweisen.
- Schauen Sie sich den Anfang des Stack-Trace an : Der Anfang des Stack-Trace (der letzte Methodenaufruf in der Liste) ist normalerweise der Punkt, an dem die Ausnahme oder der Fehler aufgetreten ist. Verwenden Sie die Oberseite des Stapels als Ausgangspunkt für Ihre Analyse.
- Bereichsvariablen analysieren : Der Zugriff auf Bereichsvariablen ist ein wesentlicher Bestandteil des Verständnisses, was passiert und warum ein bestimmtes Problem auftritt. FusionReactor stellt Bereichsvariablen mithilfe von Event Snapshot bereit .
- Verfolgen Sie den Stack-Trace rückwärts : Der Stack-Trace zeigt die Reihenfolge der Methodenaufrufe, die bis zu dem Punkt geführt haben, an dem die Ausnahme oder der Fehler aufgetreten ist. Wenn Sie den Stack-Trace rückwärts verfolgen, können Sie sehen, welche Methoden in welcher Reihenfolge aufgerufen wurden. Dies wird Ihnen helfen, den Kontrollfluss in Ihrer Anwendung zu verstehen und herauszufinden, wo das Problem möglicherweise aufgetreten ist.
- Überprüfen Sie die Parameterwerte und lokalen Variablen : Wenn Sie Zugriff auf den Quellcode für die Methoden im Stack-Trace haben, können Sie die Parameterwerte und lokalen Variablen überprüfen, um festzustellen, ob sie unerwartete Werte enthalten, die möglicherweise die Ausnahme oder den Fehler verursacht haben.
- Suchen Sie nach Mustern : Manchmal kann die gleiche Ausnahme oder derselbe Fehler an mehreren Stellen in Ihrer Anwendung auftreten. Wenn sich dieselbe Ausnahme wiederholt, kann es hilfreich sein, nach Mustern oder gemeinsamen Ursachen zu suchen, die dafür verantwortlich sein könnten. Beispielsweise wird möglicherweise dieselbe Methode wiederholt aufgerufen, was auf eine unendliche Rekursion hinweisen könnte.
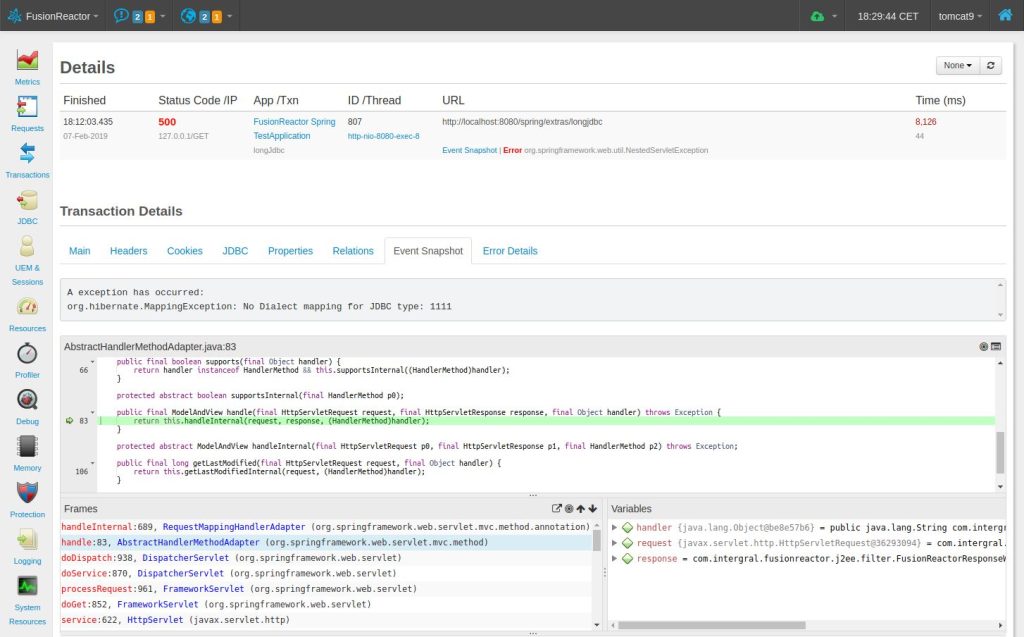
Verwendung von FusionReactor zur automatischen Anzeige der Stack- und Scope-Variablen
Immer wenn eine Ausnahme auftritt, erfasst FusionReactor diese Ereignisse automatisch in sogenannten Ereignis-Snapshots. Diese sollen tiefe Einblicke bieten, wann immer ein Problem auftritt, z. B. eine Ausnahme oder eine Thread-Latenz. Snapshots werden automatisch ausgelöst und ermöglichen es Ihnen, Quellcode, Bereichsvariablen, Stack-Trace und Protokollierungsinformationen an der Stelle im Code anzuzeigen, an der das Problem auftritt. Wir stellen Ihnen alles zur Verfügung, was Sie benötigen, um das Problem so schnell und effizient wie möglich einzugrenzen. Das Bild unten zeigt ein Beispiel für einen Event-Snapshot-Stack-Trace, Code-Rendering und Informationen zum Variablenbereich.
Fazit – So verstehen und interpretieren Sie Java-Stack-Traces zum Debuggen von Problemen
Zusammenfassend lässt sich sagen, dass Java-Stack-Traces ein wertvolles Werkzeug zum Debuggen von Problemen in Ihrer Java-Anwendung sind. Durch das Verständnis und die Interpretation des Stack-Trace können Sie die Fehlerquelle schnell lokalisieren und das Problem beheben. Es ist wichtig, zunächst den Anfang des Stack-Trace zu betrachten, wo die Ausnahme aufgetreten ist, und dann die Methodenaufrufe zu überprüfen, die zur Ausnahme und zum ersten Aufruf geführt haben. Denken Sie daran, dass der Stack-Trace abgeschnitten werden kann. Daher ist es wichtig, das Flag -XX:-OmitStackTraceInFastThrow zu verwenden, um den vollständigen Stack-Trace zu erhalten. Wenn Sie diese Schritte befolgen, können Sie Probleme in Ihrer Java-Anwendung schnell beheben und so zu einer stabileren und effizienteren Anwendung führen.








