Warum SQL Frameworks verwenden?
Heutzutage verwenden die meisten Java- Backends permanenten Speicher, wobei SQL am Markt am dominierendsten ist. Die Standard-API für die Kommunikation mit den SQL-Datenbanken ist eine Spezifikation namens JDBC (eine Reihe von Java-Schnittstellen, die Datenbankentwickler implementieren müssen, damit die Endbenutzer über das Kabel mit der Datenbank kommunizieren können ). Das Problem besteht darin, dass die Verwendung von einfachem JDBC für einen normalen Entwickler aus folgenden Gründen schwierig ist:
- Alle Abfragen müssen manuell geschrieben werden
- Das Parsen der über die Leitung übertragenen Daten muss manuell erfolgen (mithilfe von ResultSets).
- Die meisten Methoden der JDBC-API lösen geprüfte Ausnahmen aus, die Entwickler dazu zwingen, mit Blobs von Try-Catch-Anweisungen umzugehen
- Alle Transaktionen müssen manuell geöffnet und geschlossen werden
Viele Frameworks helfen Ihnen bei der Bewältigung der oben genannten Probleme. Laut einer Umfrage von Josh Long aus dem Jahr 2022 sind dies die beliebtesten Frameworks
- JPA (Hibernate oder EclipseLink)
- Rohe JDBC-Wrapper (z. B. die Spring-basierte JDBCTemplate-Klasse)
- JOOQ
- MyBatis
Sie alle lösen die oben genannten Probleme auf unterschiedliche und einzigartige Weise. Heute möchten wir jedoch zeigen, wie FusionReactor normalen Entwicklern dabei helfen kann, Datenbanken mithilfe der aufgeführten SQL- und ORM-Frameworks zu überwachen.
Was sind ORM-Frameworks?
Object Relational Mapping ist ein Akronym, das auch als ORM bekannt ist. Es bezieht sich auf die Erstellung eines virtuellen Frameworks, das eine relationale Datenbank in einer objektorientierten Sprache (wie PHP, Java, C# usw.) umgibt. Der Name (ORM) bedeutet „Zuordnung von Objekten zu relationalen Tabellen“.
Wofür werden ORM-Frameworks verwendet?
Das ORM-Framework/die ORM-Software generiert Objekte, die die Tabellen in einer Datenbank (wie in OOP) virtuell abbilden (wie eine Karte einer Stadt). Als Entwickler verwenden Sie diese Objekte, um mit der Datenbank zu interagieren. Das Hauptziel von ORM-generierten Objekten besteht darin, den Programmierer davon abzuhalten, optimierten SQL-Code schreiben zu müssen – ORM-generierte Objekte erledigen die Arbeit für Sie.
What are ORM Frameworks?
Object Relational Mapping is an acronym that is also known as ORM. It refers to creating a virtual framework that encircles a relational database in an object-oriented language (such as PHP, Java, C#, etc…). The name (ORM) translates as mapping objects to relational tables.
What are ORM Frameworks used for?
The ORM framework/software generates objects that virtual map (like a map of a city) the tables in a database (as in OOP). You, as a developer, use these objects to interact with the database. The main objective of ORM-generated objects is to shield the programmer from having to write optimized SQL code – ORM-generated objects do the job for you.
So überwachen Sie SQL- und ORM-Frameworks mit Hibernate
Hibernate ist eines der ältesten und ausgereiftesten ORM-Frameworks in der Java-Welt. Da es sich um eine JPA-Implementierung handelt, löst es JDBC-Probleme, indem es direkte, persistente Datenbankzugriffe durch Objektverarbeitungsfunktionen auf hoher Ebene ersetzt. Das wichtigste Feature ist die Abbildung von Java-Klassen in entsprechende SQL-Tabellen. Hibernate nutzt die Datenmanipulation über die Java-Klassen und generiert geeignete SQL-Anweisungen. Um Hibernate mit FusionReactor zu testen, verwenden wir ein einfaches SpringBoot-Projekt mit Spring-Data als noch höherer Abstraktionsebene gegenüber Hibernate. Hier ist das Schema:
CREATE TABLE users ( ID BIGINT PRIMARY KEY AUTO_INCREMENT, name varchar(255) ); create table orders ( ID BIGINT PRIMARY KEY AUTO_INCREMENT, price double precision, user_id BIGINT references users (ID) );
Ein Benutzer hat viele Bestellungen. Zunächst müssen wir Mapping-Klassen für beide Tabellen generieren (Lombok wird zur automatischen Generierung von POJO-Methoden verwendet):
@Entity @Data @Table(name = "users") class User { @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; @Column(name = "name") private String name; @OneToMany(cascade = CascadeType.ALL) @JoinColumn(name = "user_id") private Set<Order> items = new HashSet<>(); } @Table(name = "orders") @Entity @Data @NoArgsConstructor @AllArgsConstructor class Order { @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; private double price; private String name; @ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "user_id") private User user; Order(double price, String name) { this.price = price; this.name = name; } }
Als nächstes müssen wir eine Repository-Schnittstelle erstellen:
public interface UserRepository extends JpaRepository<User, Long> {
}
FAls nächstes müssen wir eine Repository-Schnittstelle erstellen:
spring.datasource.url=jdbc:h2:mem:testdb
spring.data.jpa.repositories.bootstrap-mode=default
In den letzten beiden Zeilen können Sie ein von Hibernate generiertes formatiertes SQL in der Konsole anzeigen. Um es zu testen, verwenden wir schließlich einen einfachen Rest Controller, der:
- Wird bei jedem fünften Aufruf ausgelöst
Thread.sleep, um lang laufende Abfragen zu simulieren - Löst bei jedem dritten Aufruf eine Ausnahme aus, um einen Fehler auf Geschäftsebene zu simulieren
@RestController
@RequestMapping("/users")
public class UserController {
private final UserRepository userRepository;
@GetMapping("/save")
public Long save() {
final int condition = this.cnt.getAndIncrement();
if (condition % 2 == 0) {
TimeUnit.SECONDS.sleep(3);
}
final User user = new User();
user.setName(UUID.randomUUID().toString());
user.setItems(
Set.of(
new Order(12.0, "Banana"),
new Order(12.0, "Apple")
)
);
this.userRepository.save(user);
if (condition % 5 == 0) {
throw new RuntimeException("Business error");
}
return user.getId();
}
}
Lassen Sie uns etwas Datenverkehr an das Backend senden und sehen, welche Insider FusionReactor uns bietet:
#!/bin/bash
for i in {1..100}
do
curl http://localhost:8080/users/save
done
(Der Quellcode ist hier verfügbar )
Transaktionsdetails
Zunächst können wir alle DB-Transaktionen auflisten (Transaktionen -> Verlauf).
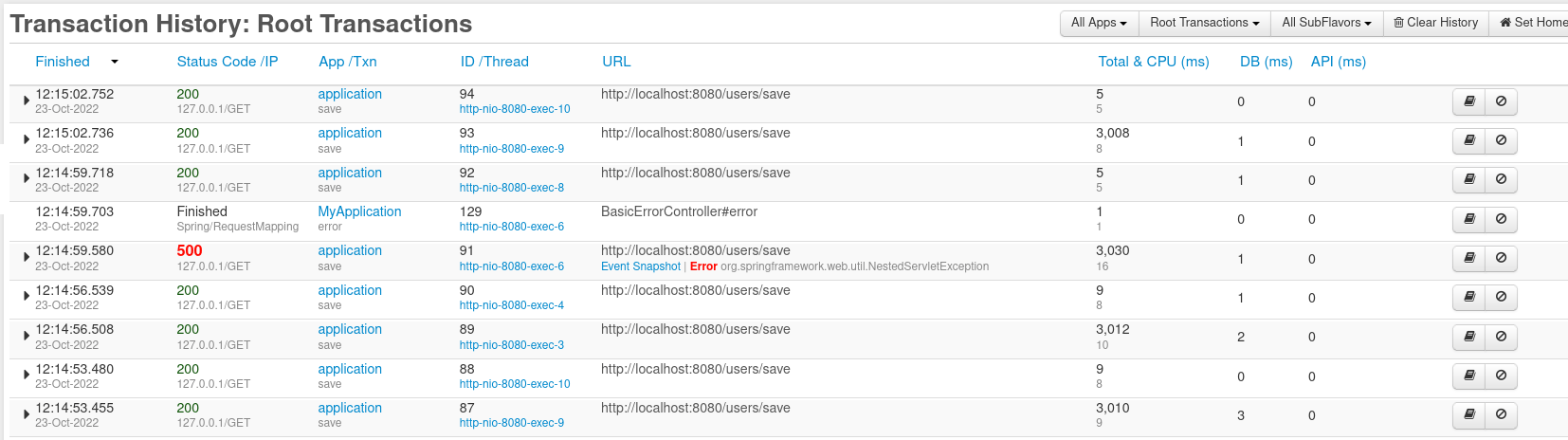
Wie Sie sehen, sind einige von ihnen fehlgeschlagen, andere brauchten 3000 ms (3 Sekunden) und waren erfolgreich, und andere dauerten nur wenige Millisekunden. Mal sehen, ob FusionReactor uns helfen kann zu verstehen, warum einige dieser Transaktionen fehlgeschlagen sind. Wenn Sie auf die Schaltfläche „Details“ (das Buchsymbol neben der Transaktion) klicken, wird die Seite mit allen Transaktionsdetails angezeigt:

Erstens sind drei Links spezifisch für HTTP-Anfragen, daher überspringen wir sie jetzt und konzentrieren uns weiterhin auf den SQL-Teil.
JDBC
Auf der JDBC-Seite finden Sie die JDBC-Zusammenfassung
- Die Zeit, die zum Ausführen aller Abfragen benötigt wurde
- Alle von der Transaktion ausgeführten Abfragen
Eine einzelne Transaktion führte acht Abfragen aus. Dies ist nicht das Ergebnis, das Sie durch das Speichern eines einzelnen Benutzers mit zwei Bestellungen erzielen möchten.
Beziehungen
Die Seite „Beziehungen“ ist besonders nützlich, da sie Ihnen alle Abfragen in einer hierarchischen Reihenfolge anzeigt:
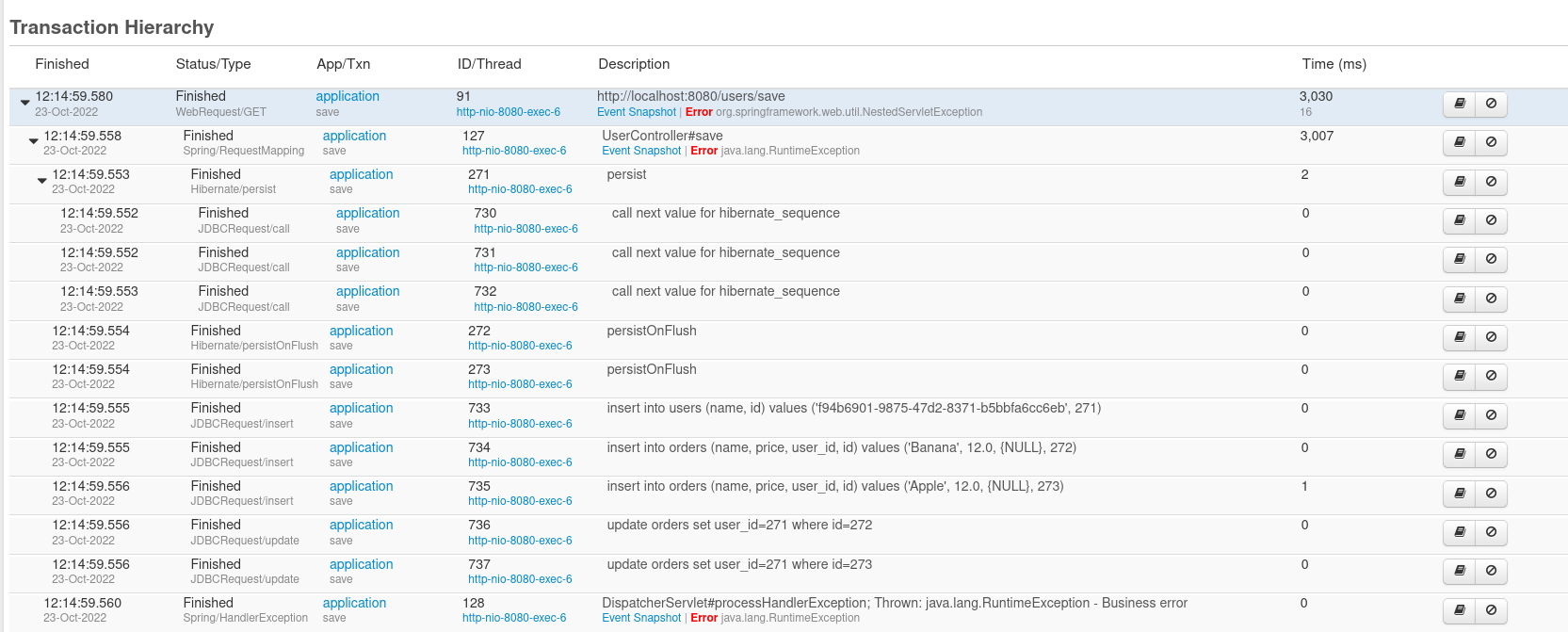
Lassen Sie uns diese Liste aufschlüsseln
- Hibernate hat aus den angegebenen Sequenzen 3 Primärschlüssel generiert
- 1 Abfrage zum Einfügen des Benutzers
- 2 Abfragen zum Einfügen von zwei Bestellungen (beachten Sie, dass user_id für beide Bestellungen null ist)
- 2 Aktualisierungsabfragen, um die Benutzer-ID auf neu erstellte Bestellungen festzulegen
(Wenn Sie wissen möchten, wie Sie die Zuordnung optimieren können, um die Anzahl der Abfragen zu verringern, empfehlen wir Ihnen diesen wunderbaren Blogbeitrag von Vlad Mihalcea.)
Event Snapshot
Eine weitere wichtige Seite, die Ihnen helfen kann, die Grundursache des Fehlers zu verstehen, ist Event Snapshot:
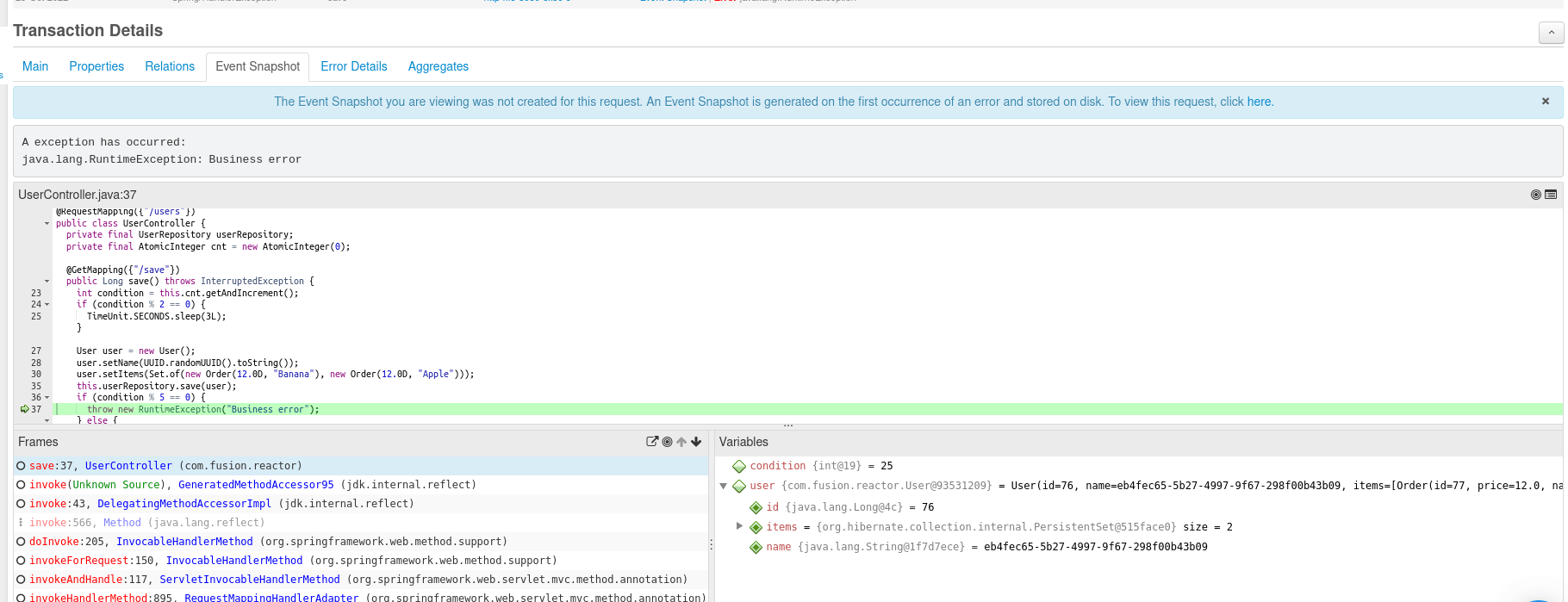
Diese Seite zeigt Ihnen Folgendes:
- Der dekompilierte Quellcode zeigt Ihnen die Zeile, in der dieser Fehler ausgegeben wurde
- Der Stack-Trace in der linken unteren Ecke kann Ihnen helfen, den Anforderungszyklus zu verstehen
- Die Variablenseite unten rechts zeigt Ihnen alle Variablen, die vor dem Fehler vorhanden waren (der
conditionint war 25).
JDBC
Alle oben beschriebenen Insider waren nur ein Teil der Transaktionsseite. FusionReactor kann Ihnen auf der JDBC-Seite noch viel mehr zeigen:
Einstellungen
Mit dieser Einstellung können Sie das FusionReactor-Verhalten auf unterschiedliche Weise anpassen, angefangen bei der Festlegung Ihres Schwellenwerts für lange Transaktionen bis hin zur Erstellung eines Abfrageplans für lange Transaktionen (hilft Teams bei der Entscheidung, ob die jeweilige Abfrage von der Einführung eines Index profitiert). Standardmäßig kann Spring Boot von Hibernate generierte SQL-Abfragen generieren und drucken. Diese Funktion ist zwar nützlich, weist jedoch eine Einschränkung auf: Alle vorbereiteten Anweisungsparameter werden mit Platzhaltern ausgeblendet ?. Andererseits zeigt FusionReactor, wie Sie bereits gesehen haben, die Abfragen mit allen entsprechenden SQL-Argumenten an. Während diese Funktion in der lokalen Entwicklung hilfreich sein kann, wo Sie die SQL-Anweisung direkt kopieren und in das RDMS Ihrer Wahl einfügen können, um einige Tests durchzuführen, kann die Funktion in der Produktionsumgebung gefährlich sein, wenn Benutzeranmeldeinformationen verloren gehen, wenn Kunden versuchen, sich anzumelden zu Ihrer Bewerbung. Wir empfehlen dringend, diese Funktion in der Produktion zu deaktivieren, was auf der Einstellungsseite erfolgen kann.
Längste Transaktionen
Einer der Hauptunterschiede zwischen den Seiten „Longest Transactions in Request“ und JDBC besteht darin, dass die JDBC-Seite nur anzeigt, wie lange jede SQL-Abfrage gedauert hat:
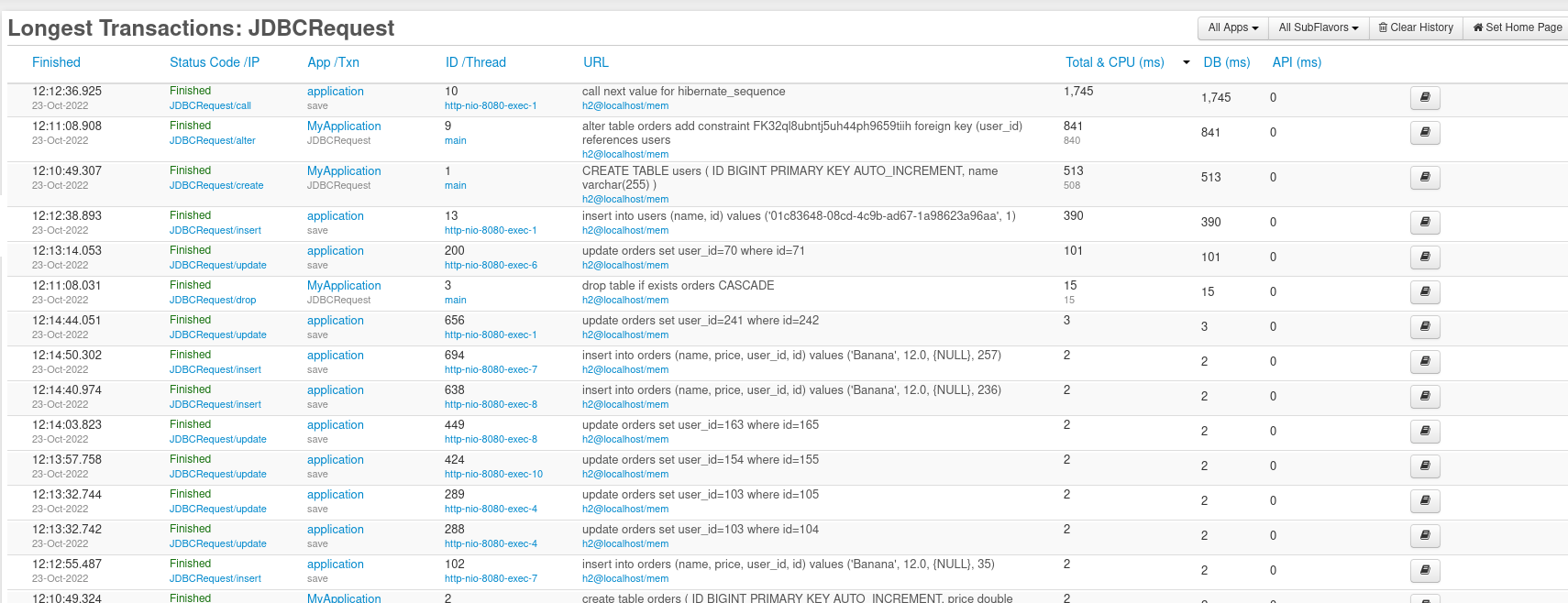

Wie Sie sehen, gibt es keine Transaktionen, die 3 Sekunden gedauert haben, da Thread.sleepdas, was wir auf der Controller-Ebene aufrufen, nicht Teil der Abfrage ist. Eine weitere Sache ist, dass alle Transaktionen in dieser Liste erfolgreich waren; Auch wenn Java einen Fehler auslöst, hat dies keinen Einfluss darauf, ob die Abfrage selbst fehlschlägt. Als Beispiel ändern wir das Schema ein wenig und machen den Bestellnamen ( name varchar(255) unique) eindeutig. Wenn Sie in diesem Fall versuchen, denselben Auslastungstest erneut auszuführen, werden Sie feststellen, dass einige Transaktionen fehlgeschlagen sind:
Wenn Sie wie immer auf die Detailseite klicken, werden Ihnen Veranstaltungsschnappschüsse mit detaillierten Informationen angezeigt.
Grafiken
Um die JDBC-Statistiken besser zu visualisieren, stellt FusionReactor zwei Grafiken zur Verfügung:
- Zeitdiagramm
- Aktivitätsdiagramm
Das Zeitdiagramm zeigt die historische durchschnittliche Dauer der folgenden JDBC-Anfragen:
- Vollendet
- Aktiv
- Fehlgeschlagen
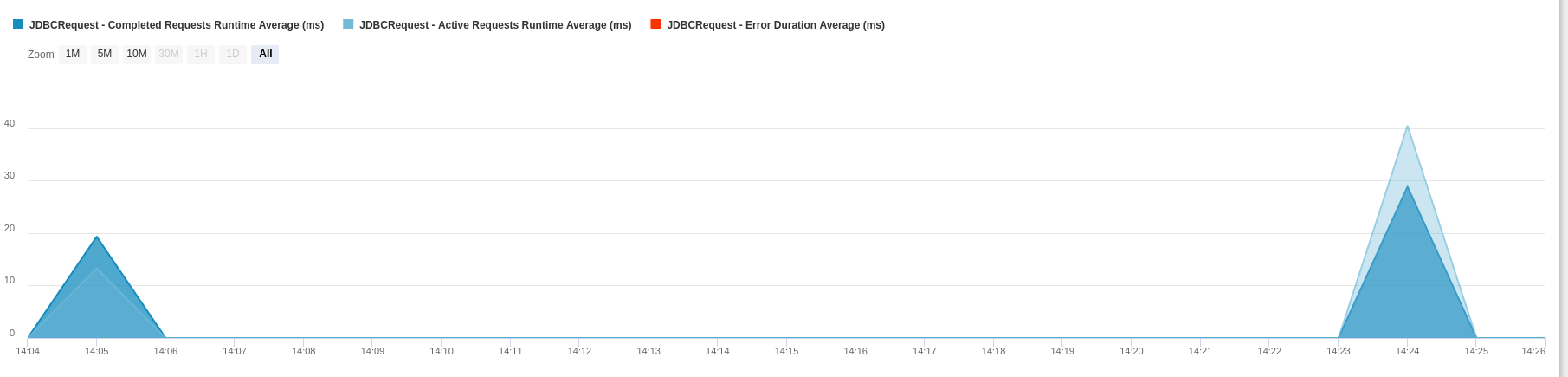
Das Zeitintervall ist konfigurierbar und alle Transaktionen bleiben bestehen. Das Aktivitätsdiagramm zeigt Ihnen die Anzahl der aufgelisteten Anfragen. Folglich kann es Ihnen helfen, den Spitzenverkehr auf Ihren Websites zu visualisieren.
Datenbank
Zu guter Letzt gibt es eine Datenbankseite, die Ihnen mithilfe von Kreisdiagrammen eine schöne Aufschlüsselung aller JDBC-Aktivitäten zeigt:

Die Kreisdiagramme zeigen es Ihnen
- Gesamtzeit nach Abfragen
- Gesamtzeit nach Tischen
- Die Abfrage wird nach Vorgang gezählt
- Abfrage zählt nach Tabelle
Metriken
Einer der wichtigsten von JVM unterstützten Metriktypen ist JMX. Konfigurierte JMX-Beans können zur Laufzeit überwacht und neu konfiguriert werden. Einer der wichtigsten zu überwachenden Teile in Backend-Apps ist das Pooling von Datenbankverbindungen. Standardmäßig konfiguriert Spring den Hikari-Verbindungspool vor. Durch das Hinzufügen dieser Zeile zu Ihrer Konfigurationsdatei spring.datasource.hikari.register-mbeans=truewerden entsprechende MBeans generiert, die Sie auf der Seite „FusionReactor-Metriken“ sehen können :
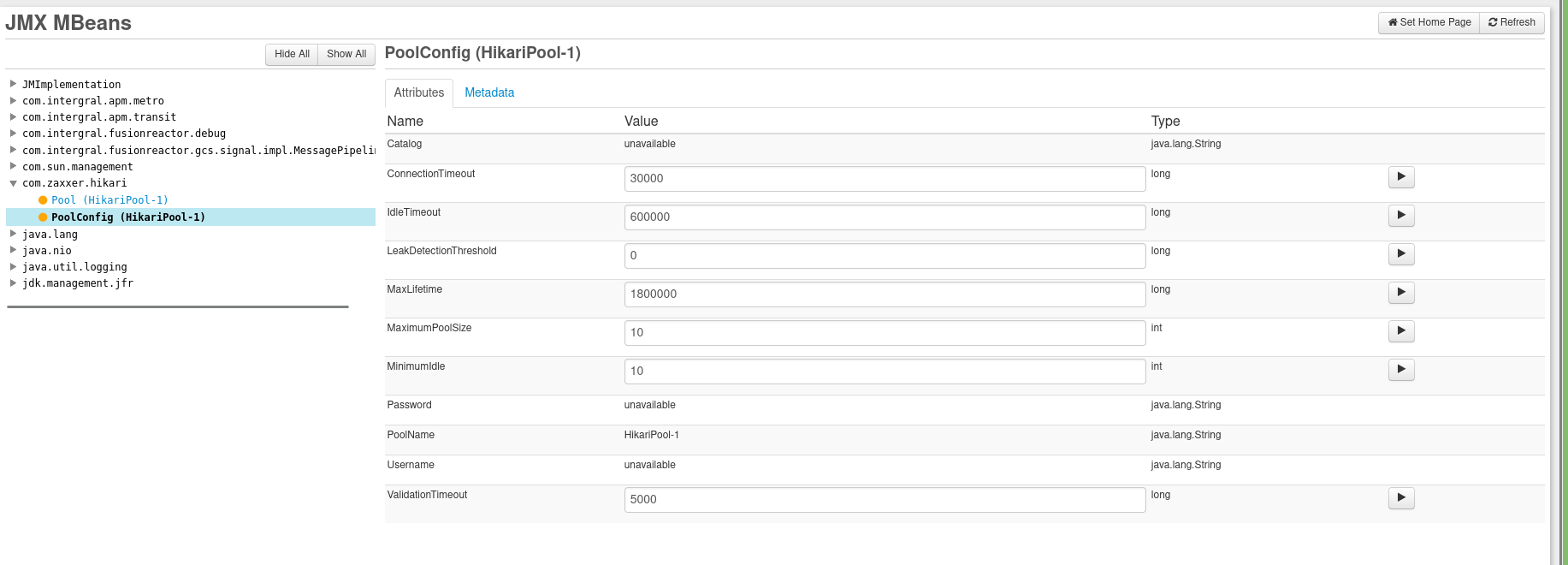
Alle Einstellungen sind konfigurierbar und können über das Startsymbol überwacht werden. Die Metriken können dann nach CloudWatch exportiert werden, wenn Sie eine AWS-Infrastruktur verwenden.
Fallstricke im Hibernate
Hibernate als Framework hat eine tiefe Lernkurve. Unter der Haube findet eine Menge Reflexionsmanipulation statt. In Spring Boot wird die Datenbanktransaktion standardmäßig auf Controller-Ebene geöffnet. Warum passiert das? Wenn Sie eine Entität mit einer Lazy-Sammlung laden und die Sammlung dann verwenden möchten, löst die Sitzung auf Controller-Ebene eine separate SQL-Abfrage aus, um die Daten für diese Sammlung aus der Datenbank abzurufen. Das Problem hierbei ist, dass Datenbanktransaktionen geöffnet werden müssen, sobald sie benötigt werden (vorzugsweise in der Serviceschicht). Andernfalls zwingen die Transaktionen mit langer Laufzeit den Verbindungspool dazu, neue DB-Verbindungen zu erstellen, um neue Benutzer zu bedienen. Um dieses Verhalten zu deaktivieren, müssen Sie diese Zeile in Ihre Konfigurationsdatei übergeben spring.jpa.open-in-view=false. Lassen Sie uns den Auslastungstest noch einmal durchführen. Wenn Sie jedoch den JDBC-Verlauf überprüfen, werden Sie keine Anomalien feststellen. Wenn Sie jedoch die Seite „Transaktionsdetails“ öffnen Transactions->History und dann zu „Beziehungen“ gehen , um die Transaktionsaufschlüsselung anzuzeigen, werden Sie feststellen, dass Hibernate drei separate Transaktionen statt einer geöffnet hat:
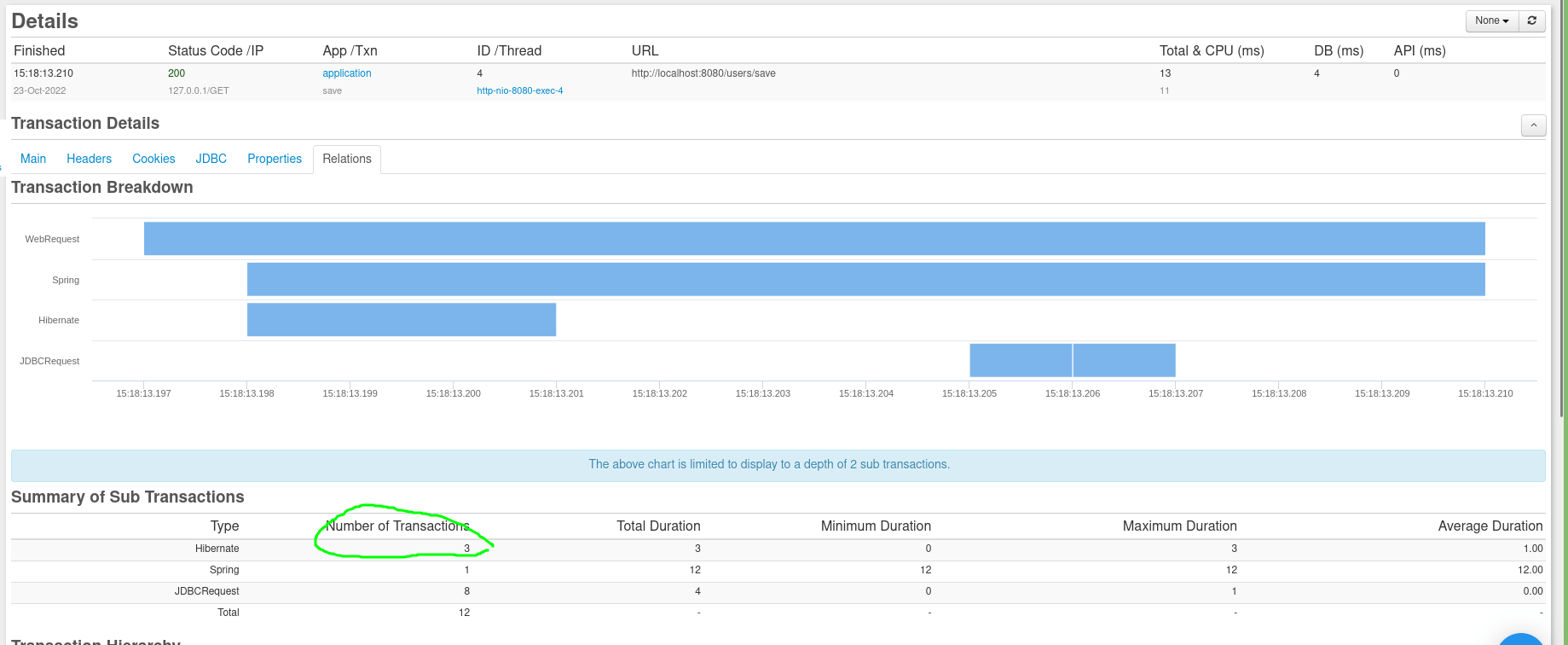
Um dieses Problem zu beheben, fügen Sie @Transactional der saveMethode eine Anmerkung hinzu.
So überwachen Sie SQL- und ORM-Frameworks mit MyBatis
Wie wir gesehen haben, vereinfacht Hibernate die persistente Schicht. Allerdings muss der Entwickler verstehen, was unter der Haube vor sich geht, um das Verhalten des Standard-Frameworks zu optimieren. Andererseits gibt es ein anderes beliebtes Java-Framework, das unter der Haube nicht viel „schwarze Magie“ betreibt, nämlich MyBatis. Laut Dokumentation
MyBatis ist ein erstklassiges Persistenz-Framework mit Unterstützung für benutzerdefiniertes SQL, gespeicherte Prozeduren und erweiterte Zuordnungen
Die Entwickler, die MyBatis verwenden, haben die volle Kontrolle über die SQL-Abfragen mithilfe eines benutzerfreundlichen XML oder einer annotationsbasierten API (mit der Einführung mehrzeiliger Strings in Java 14 sollte die Annotation API bevorzugt werden). Schreiben wir das vorherige Beispiel mit MyBatis neu. Zunächst müssen wir alle JPA-spezifischen Anmerkungen aus Entity-Klassen entfernen. Als nächstes müssen wir SQL mithilfe von XML-Dateien selbst schreiben. Für dieses Beispiel werden wir die Repository-Klasse neu schreiben, die den Benutzer mit entsprechenden Bestellungen speichert (Codebeispiele finden Sie hier ). Hier ist die Mapper-Klasse:
@Mapper public interface UserMapper { void saveUser(User user); void saveOrders(@Param("orders") List<Order> orders, @Param("userId") long userId); default void saveUserWithOrders(User user) { this.saveUser(user); this.saveOrders(user.getOrders(), user.getId()); } }
und hier ist die entsprechende XML-Datei:
<mapper namespace="com.fusion.reactor.UserMapper"> <resultMap id="UserResultMap" type="com.fusion.reactor.User"> <id column="id" property="id"/> <result column="name" property="name"/> </resultMap> <insert id="saveUser" parameterType="com.fusion.reactor.User" useGeneratedKeys="true" keyProperty="id" keyColumn="id"> INSERT INTO users (name) VALUES (#{name}) </insert> <insert id="saveOrders" parameterType="map"> INSERT INTO orders ( price,user_id,name ) VALUES <foreach collection="orders" item="order" index="index" open="(" separator="),(" close=")"> #{order.price}, #{userId}, #{order.name} </foreach> </insert> </mapper>
Wie Sie sehen, haben wir explizit zwei Abfragen geschrieben, erstens zum Speichern des Benutzers und zweitens zum Speichern einer Bestellliste. Keine automatisch generierten Abfragen und keine automatische Zuordnung wie in Hibernate, und alles muss manuell erledigt werden. Lassen Sie uns die Auslastungstests erneut ausführen und den JDBC-Transaktionsverlauf anzeigen.

FusionReactor zeigt Ihnen, dass MyBatis die von Ihnen angegebenen Abfragen mit allen angezeigten Parametern generiert hat, sodass Sie überprüfen können, ob Mapper wie erwartet funktionieren. Wenn Sie die Seite „Beziehungen“ in den Transaktionsdetails für eine der Anforderungen aufrufen, können wir sehen, dass eine einzelne Anforderung 1 verwendet hat Transaktion und 2 JDBC-Abfragen:
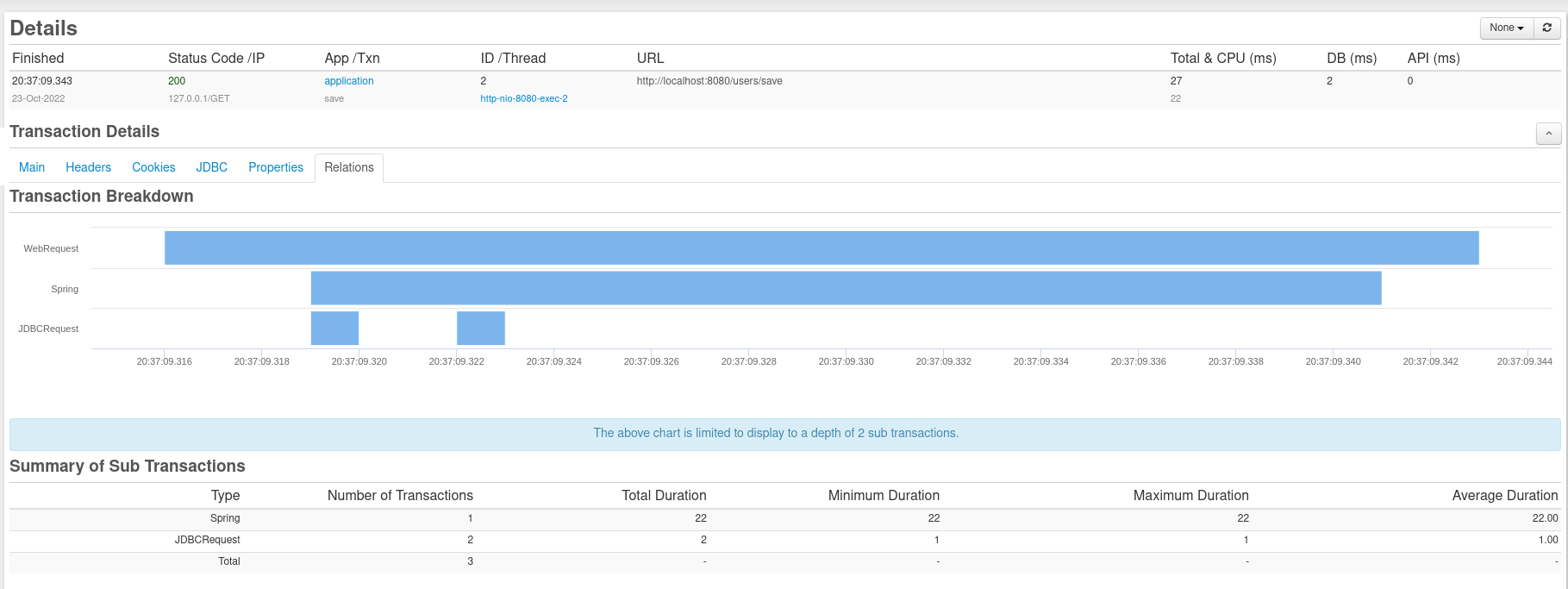
Das MyBatis-Plugin für IntelliJ bietet Sprachserverunterstützung zum Schreiben typsicherer XML-Dateien. Wenn Sie jedoch Unterstützung zur Kompilierungszeit wünschen, sollten Sie ein anderes Framework in Betracht ziehen.
So überwachen Sie SQL- und ORM-Frameworks mit JOOQ
Das letzte SQL-Framework, das wir heute behandeln werden, ist JOOQ. Laut der offiziellen Website
jOOQ generiert Java-Code aus Ihrer Datenbank und ermöglicht Ihnen über die Fluent-API die Erstellung typsicherer SQL-Abfragen.
JOOQ unterscheidet sich von den beiden vorherigen Frameworks, da es zur Kompilierungszeit Java-Klassen aus SQL-Tabellen generiert. Alle kompilierten Java-Klassen sind Teil des Klassenpfads und können während der Entwicklung abgerufen werden. Da der neueste Spring-Boot-jooq-Starter H2 nicht unterstützt, werden wir Postgres als RDMS verwenden (Quellcode ist hier verfügbar ). Zuerst müssen wir ausführen, mvn clean installum Java-Klassen zu generieren. Als Nächstes schreiben wir dieselbe Abfrage, die den Benutzer und zwei Bestellungen speichert, jedoch mit der JOOQ-API:
@RestController @RequestMapping("/users") public class UserController { @Autowired private DSLContext dslContext; @GetMapping("/save") public long save() { final Record1<Integer> id = this.dslContext.insertInto(Tables.USERS) .columns(Tables.USERS.NAME) .values(UUID.randomUUID().toString()) .returningResult(Tables.USERS.ID) .fetchOne(); final Integer userId = id.getValue(Tables.USERS.ID); this.dslContext.insertInto(Tables.ORDERS) .columns(Tables.ORDERS.USER_ID, Tables.ORDERS.NAME, Tables.ORDERS.PRICE) .values(userId, "Banana", 12.5) .values(userId, "Apples", 13.0) .execute(); return userId; } }
FusionReactor funktioniert mit JOOQ genauso wie mit allen anderen Frameworks. Alle generierten Klassen werden in der JAR-Datei gespeichert, sodass Sie nichts weiter tun müssen, um JOOQ mit FusionReactor zu integrieren. Nach dem Ausführen des Lasttests können wir auf der Registerkarte „JDBC-Verlauf“ sehen, dass JOOQ zwei SQL-Abfragen verwendet:

JOOQ ist aufgrund der Überprüfung der Kompilierungszeit durch den Compiler, der Syntaxhervorhebung durch Ihren Editor und der automatischen Zuordnung von SQL-Tabellen zu Java-Klassen einfacher zu verwenden als MyBatis. Es ist jedoch nicht so leistungsstark wie Hibernate, da Sie alle Abfragen immer noch selbst schreiben müssen.
So überwachen Sie SQL- und ORM-Frameworks – Fazit
Alle drei Frameworks haben ihre Nische unter Java-Entwicklern. Heutzutage bevorzugen die meisten Unternehmen jedoch Hibernate, um die Entwicklungszeit zu verkürzen, während andere Unternehmen leichtere Frameworks wie JOOQ und MyBatis bevorzugen, um die volle Kontrolle über SQL zu haben und dadurch optimierteren Code zu schreiben, ohne auf von JPA generiertes SQL angewiesen zu sein . FusionReactor unterstützt alle diese Frameworks und kann Ihnen Einblicke in die zugrunde liegenden SQL-Abfragen geben, die von Ihrem Code ausgeführt werden, sowie Leistungsmetriken für jede Abfrage. Wie Sie gesehen haben, ist es mit FusionReactor wirklich einfach zu erkennen, ob sich Hibernate wie erwartet verhält. Bei Interesse buchen Sie bitte eine Demo bei uns oder laden Sie eine Testversion herunter .








