So überwachen Sie Nicht-Heap-Speicher mit FusionReactor
Um den Nicht-Heap-Speicher zu überwachen , müssen wir zunächst verstehen, was er ist. Nicht-Heap-Speicher bezieht sich auf nativen Speicher, den die JVM für einige ihrer Vorgänge verwendet. Dieser Speicher wird für Vorgänge wie das Speichern von Bytecode, Klassenmetadaten und Thread-Zuweisung verwendet.
In diesem Tutorial erfahren Sie, wie FusionReactor Ihnen bei der Überwachung und Verwaltung von Nicht-Heap-Speicher helfen kann .
1. Code-Cache
Code-Cache ist der Speicherplatz, der zum Speichern von Java- Bytecode im nativen Speicher verwendet wird . Der Code-Cache ist in drei separate Segmente unterteilt: Nicht-Methoden-, Profil- und Nicht-Profil-Code-Heaps.
- Der Nicht-Methoden-Heap speichert Nicht-Methodencode wie Compiler-Puffer. Dieses Segment hat eine feste Größe von etwa 3 MB und bleibt für immer im Code-Cache.
- Laut Oracle enthält der profilierte Heap Folgendes:
leicht optimierte, profilierte Methoden mit kurzer Lebensdauer.
- Auf derselben Seite wie oben heißt es, dass das nicht profilierte Segment „vollständig optimierte, nicht profilierte Methoden mit potenziell langer Lebensdauer“ enthält.
Die abgestufte Kompilierung, die der Code-Cache verwendet, gewährleistet eine bessere Leistung als ein nicht abgestufter Code-Cache-Block. Allerdings geht dies mit einem erheblichen Speicherkompromiss einher. Das heißt, die Menge an Code, die bei der mehrstufigen Kompilierung generiert wird, ist fünfmal so groß wie die bei der nicht-gestuften Kompilierung.
In Ihrem FusionReactor-Dashboard ( Ressourcen > Speicherbereiche ) können Sie drei Diagramme sehen, die zeigen, wie Ihre Anwendung den Code-Cache verwendet. Die drei Diagramme sind: CodeHeap ‘non-nmethods’ , CodeHeap ‘non-profiled nmethods’ und CodeHeap ‘profiled nmethods’.
Die folgende Grafik gilt für nicht profilierte Methoden:
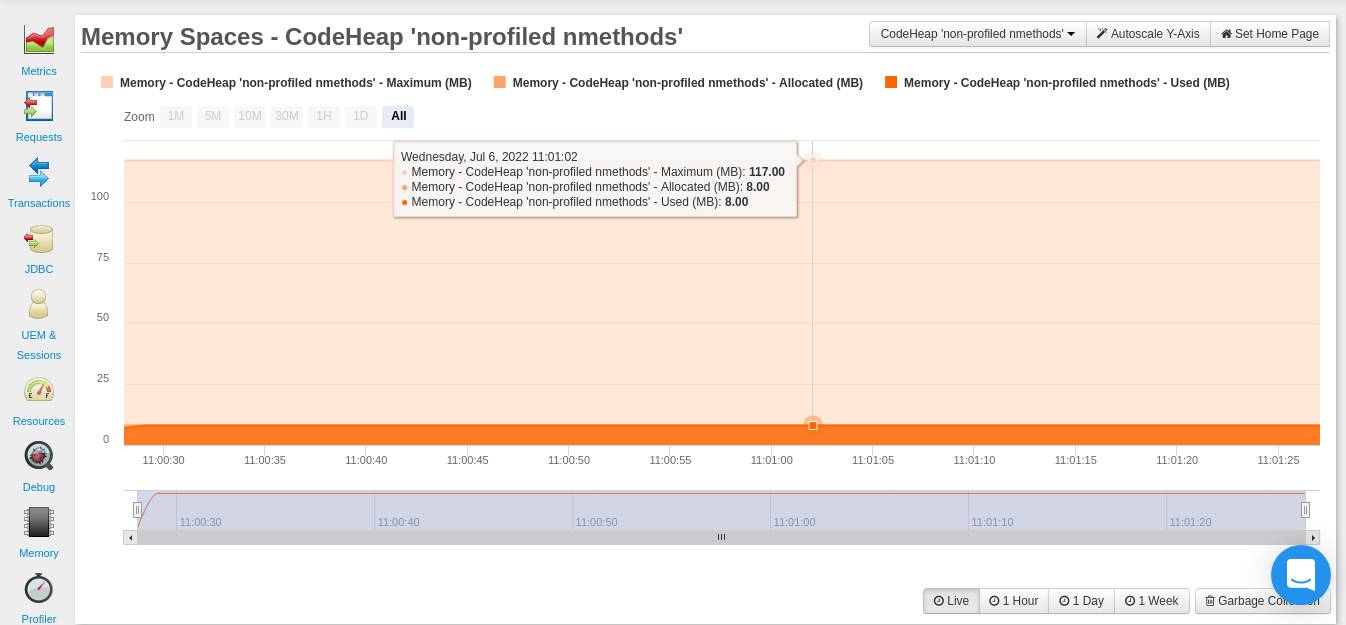
Nachdem Sie sich die Diagramme in Ihrem FusionReactor-Dashboard angesehen haben, stellen Sie möglicherweise fest, dass diesen Segmenten eine beträchtliche Menge an Speicher zugewiesen wurde. Sie können ihre Größe mit den folgenden JVM- Optionen festlegen: -XX:NonProfiledCodeHeapSize, -XX:ProfiledCodeHeapSize, -XX:NonMethodCodeHeapSize. Alle diese Größen sind in Bytes angegeben.
Wie bereits erwähnt, benötigt ein segmentierter Code-Cache viel mehr Speicher als der nicht segmentierte. Darüber hinaus kann die Festlegung fester Größen für jedes Segment zu Speicherverschwendung führen, wenn beispielsweise ein Segment voll ist, ein anderes jedoch über freien Speicherplatz verfügt.
Die JVM bietet die Möglichkeit, die Segmentierung mithilfe des Flags -XX:-TieredCompilation zu deaktivieren. Wenn Sie dieses Flag verwenden, kann FusionReactor auch erkennen, dass der Code-Cache nicht mehr segmentiert ist. Daher können Sie die zuvor erwähnten Diagramme nicht mehr sehen. Stattdessen sehen Sie ein Diagramm für CodeCache :
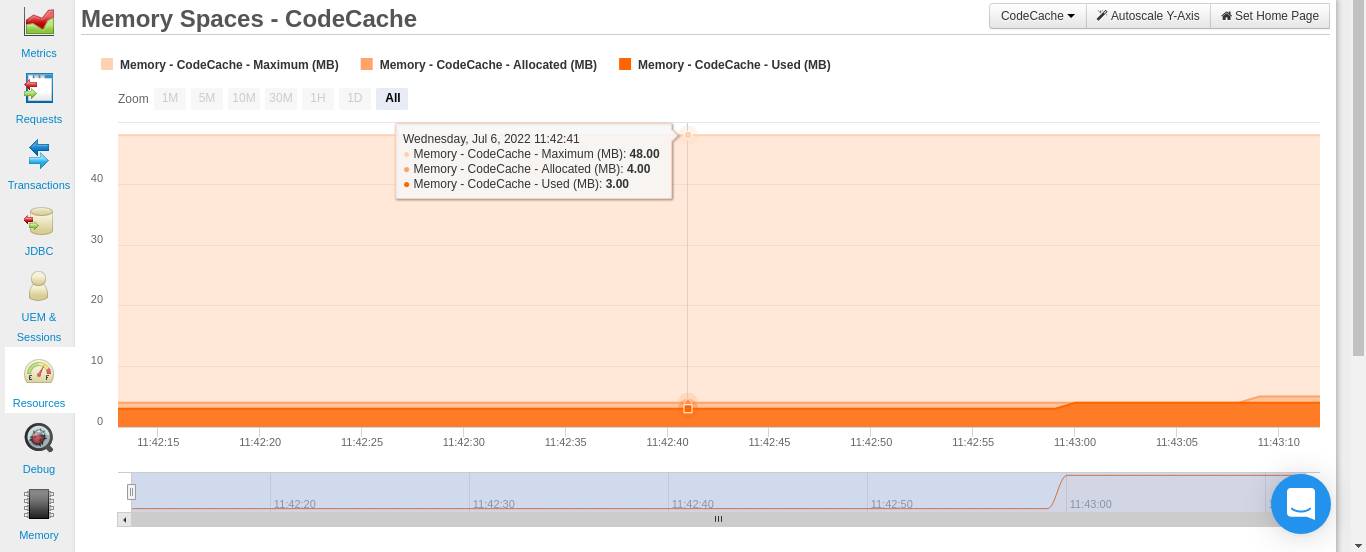
Auch nach der Deaktivierung der Segmentierung gibt es noch eine Reihe von Möglichkeiten, den Speicherverbrauch des JIT zu reduzieren. Allerdings sind diese Methoden mit geringen Leistungseinbußen verbunden. Daher müssen Sie auch die Leistung Ihrer Anwendung überwachen , während Sie diese Maßnahmen ergreifen.
Im Folgenden finden Sie drei Möglichkeiten, wie Sie die von der JIT verwendete Speichermenge reduzieren können:
Reduzierung der Anzahl der Kompilierungen
Sie können dies erreichen, indem Sie die Geschwindigkeit reduzieren, mit der die Kompilierung durchgeführt wird. Es gibt zwei JVM-Optionen, die diese Rate beeinflussen: -XX:CompileThreshold und -XX:OnStackReplacePercentage .
Die Option CompileThreshold beeinflusst die Anzahl der Methodenaufrufe, bevor eine Methode kompiliert wird. Die Option „OnStackReplacePercentage“ ist ein Prozentsatz, der die Anzahl der Rückwärtsverzweigungen beeinflusst, die eine Methode vor der Kompilierung durchführt.
Sie müssen den Wert dieser Optionen erhöhen, um reduzierte Kompilierungen zu erreichen. Ein idealer Ausgangspunkt wäre die Verdreifachung der Standardwerte für Ihre Client-JVM. Für die Server-JVM ist es möglicherweise nicht erforderlich, den Wert von CompileThreshold anzupassen
, da der Standardwert ziemlich hoch ist.
Sie können die Standardwerte überprüfen, indem Sie den folgenden Befehl verwenden:
java -XX:+PrintFlagsFinal
Sie können nun die beiden genannten Optionen schrittweise anpassen und dabei den Code-Cache-Speicherplatz in Ihrem FusionReactor-Dashboard beobachten (Ressourcen > Speicherplätze > Code-Cache). Wenn Sie mit der Maus über das Diagramm fahren, können Sie den maximalen, zugewiesenen und genutzten Speicherplatz sehen.
Reduzieren der Code-Cache-Größe
Manchmal verfügt eine Anwendung zu Beginn über viele Kompilierungen, später jedoch nur noch über sehr wenige Kompilierungen, während das Programm ausgeführt wird. In einem solchen Fall kann es hilfreich sein, die standardmäßige Code-Cache-Größe (dh die maximale Größe, die dem JIT-Compiler zugewiesen wird) einzuschränken.
Um dies festzulegen, wird die Option -XX:ReservedCodeCacheSize verwendet. Die Idee besteht darin, diesen Wert (in MB) so zu reduzieren, dass der Compiler gezwungen wird, nicht mehr verwendete Methoden zu löschen.
Sie optimieren die Größe -XX:ReservedCodeCacheSize , indem Sie versuchen, den verwendeten Code-Cache so zu gestalten, dass er nahe am maximalen Code-Cache liegt.
Reduzieren der Größe kompilierter Methoden
Dies beinhaltet die Reduzierung des Inlinings, das der Compiler beim Kompilieren von Methoden durchführt. Unter Inlining versteht man das Einfügen des Codes einer anderen Methode in eine andere kompilierte Methode. Die JVM verwendet standardmäßig bestimmte Heuristiken, um die zu verwendende Inlining-Technik zu bestimmen, mit dem allgemeinen Ziel, die Leistung zu optimieren.
Sie können einige Leistungsvorteile gegen einen reduzierten Code-Cache eintauschen. Im Folgenden finden Sie einige Optionen, die Sie für das Methoden-Inlining verwenden können:
-XX:InlineSmallCode
-XX:MaxInlineLevel
Weitere Informationen zu den verfügbaren Inlining-Optionen finden Sie auf dieser Oracle-Seite.
2. Metaraum
Der Metaspace ist ein nativer Speicher, der zum Speichern von Metadaten über Klassen verwendet wird. Diese Speicherzuweisung ist standardmäßig unbegrenzt. Aus diesem Grund sollten Sie überwachen, wie Ihr Metaspace wächst. Andernfalls kann es zu einem Szenario kommen, in dem der Metaspace den gesamten Speicher verbraucht.
Sie können über Ihr FusionReactor-Dashboard überwachen, wie Ihre Anwendung den Metaspace nutzt ( Ressourcen > Speicherplätze > Metaspace ).
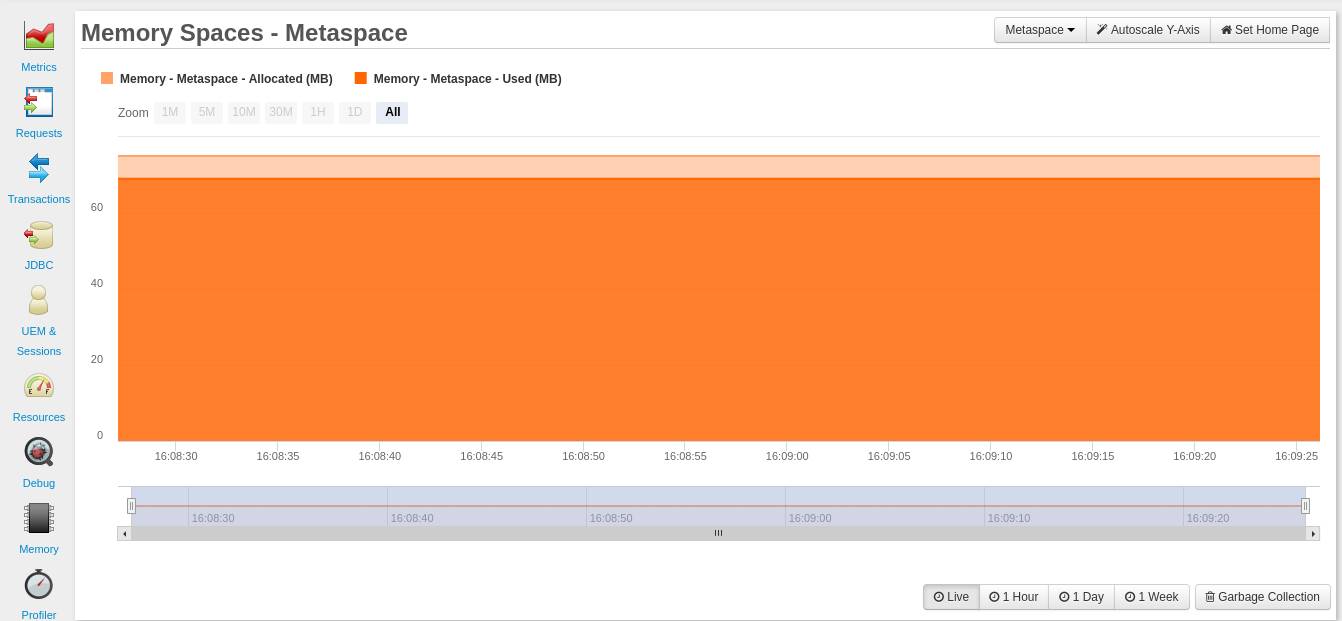
Um ein Szenario zu vermeiden, in dem dem Metaspace der gesamte Speicher ausgeht, können Sie den maximalen Wert festlegen, den er haben kann, indem Sie die JVM-Option :
-XX:MaxMetaspaceSize
verwenden . Es gibt jedoch eine Herausforderung. Wenn die Metaspace-Größe diesen Wert erreicht, stürzt das Programm aufgrund einer Ausnahme wegen unzureichendem Arbeitsspeicher ab:
java.lang.OutOfMemoryError: Metaspace .
Diese Situation ist für eine Produktionsumgebung nicht ideal. Aus diesem Grund benötigen Sie, wenn Sie Nicht-Heap-Speicher überwachen möchten, ein Überwachungs- und Warntool wie FusionReactor, um zu überwachen, wie der Metaspace wächst/genutzt wird, anstatt seinen Wert zu begrenzen.
Der den Metadaten zugewiesene Speicher wird freigegeben, wenn Klassen entladen werden. Das Entladen von Klassen erfolgt, wenn die JVM eine Speicherbereinigung durchführt. Um die Häufigkeit der Garbage Collection zu verringern, können Sie den Wert Ihrer MetaspaceSize erhöhen.
Wenn der dem Metaspace zugewiesene Speicher einen bestimmten Wert (Hochwassermarke) erreicht, wird die Speicherbereinigung eingeleitet. Die Obergrenze nimmt den Wert -XX:MetaspaceSize an . Die standardmäßige MetaspaceSize liegt zwischen 12 und etwa 20 MB und hängt von Ihrer Plattform ab.
Es ist wichtig zu beachten, dass die JVM die Obergrenze erhöhen oder verringern kann, je nachdem, wie viele Metadaten zuvor freigegeben wurden. -XX :MaxMetaspaceFreeRatio und -XX:MinMetaspaceFreeRatio bestimmen, ob die Obergrenze erhöht oder gesenkt wird.
Wenn das prozentuale Verhältnis des zugewiesenen Speicherplatzes zum verwendeten Speicherplatz für Metadaten größer als MaxMetaspaceFreeRatio ist , wird die Obergrenze gesenkt. Andererseits wird die Obergrenze angehoben, wenn dieses Verhältnis kleiner als MinMetaspaceFreeRatio ist .
Sie können diese beiden Verhältnisse anpassen, während Sie die Metaspace-Werte in Ihrem FusionReactor-Dashboard überwachen (Ressourcen > Speicherplätze > Metaspace) . Wenn Sie mit der Maus über das Diagramm fahren, können Sie den zugewiesenen (MB) Speicher für Metadaten und den verwendeten Speicher (MB) sehen.
3. Compressed Class Space
Wenn die Option -XX:UseCompressedOops aktiviert ist und -XX:UseCompressedClassesPointers verwendet wird, wird der Metaspace in zwei logisch unterschiedliche Speicherbereiche unterteilt. Diese beiden Optionen erstellen eine Zuordnung für komprimierte Klassenzeiger. Diese Zuweisung dient zum Speichern von 32-Bit-Offsets zur Darstellung der Klassenzeiger von 64-Bit-Prozessen.
Mit der Option XX:CompressedClassSpaceSize können Sie die Größe des für komprimierte Klassenzeiger zugewiesenen Speicherplatzes festlegen. Der Standardwert ist 1 GB. Es kann ein Szenario auftreten, in dem der für die Verwendung komprimierter Klassen benötigte Speicher den CompressedClassSpaceSize- Wert überschreitet. Wenn dies geschieht, stößt Ihre Anwendung auf die Ausnahme „java.lang.OutOfMemoryError: Compressed class space“ .
Sie können in Ihrem FusionReactor-Dashboard ( Ressourcen > Speicherplätze > Komprimierter Klassenraum ) überwachen, wie Ihre Anwendung die Speicherzuweisung ihrer komprimierten Klasse nutzt, um einem solchen Szenario entgegenzuwirken.
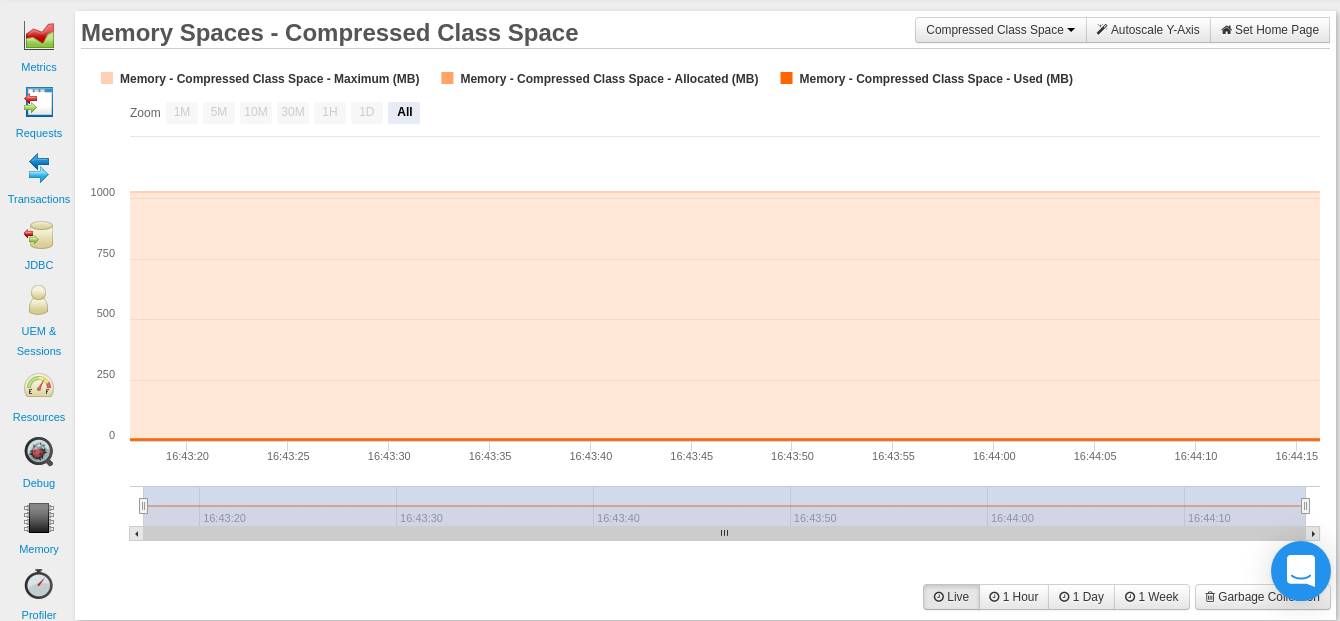
It’s important to note that the XX:MaxMetaspaceSize option applies to space for both compressed classes and for other metadata. Therefore, it’s important for you to ensure that the CompressedClassSpaceSize you’ve set is less than the MaxMetaspaceSize.
4. Garbage Collection
Unter Garbage Collection (GC) versteht man die Freigabe des Heap-Speichers, wenn dieser voll ist. Es stehen Ihnen vier Garbage Collectors zur Verfügung.
Die JVM wählt automatisch aus, welches für die Anwendung am besten geeignet ist. Am besten überlassen Sie es zunächst der JVM, den zu verwendenden Collector auszuwählen. Wenn Ihre Anwendung immer noch Probleme mit den Garbage-Collection-Zeiten hat, können Sie mit der Anpassung Ihres Heap-Speichers beginnen.
Wenn dies fehlschlägt, können Sie jetzt darüber nachdenken, einen bestimmten Garbage Collector für Ihre Anwendung auszuwählen.
In Ihrem Garbage-Collection-Diagramm sollten Sie auf häufige Garbage-Collections und lange Garbage-Collection-Zeiten achten. Die folgende Grafik ( Live- Zeitraum) zeigt, wie eine „ideale“ Häufigkeit der Speicherbereinigung aussehen würde.
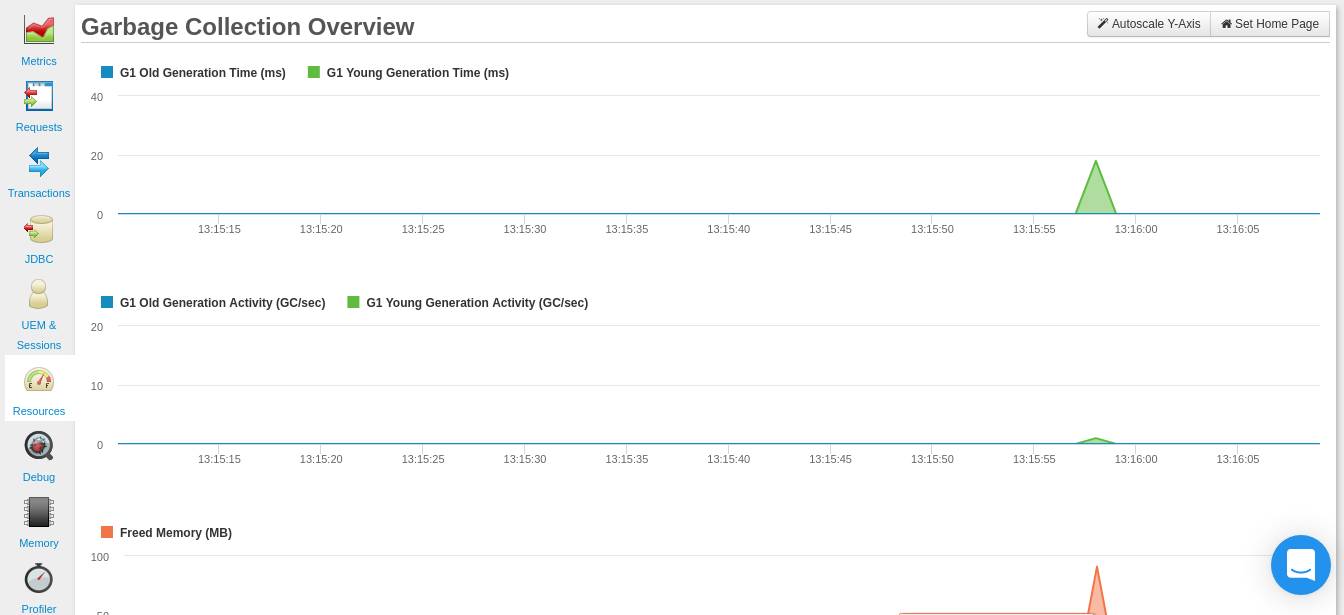
Da es sich hierbei jedoch um ein Diagramm für einen Live- Zeitraum handelt, können Sie möglicherweise nicht die herausragenden Ereignisse beobachten, nach denen Sie suchen. Daher können Sie erwägen, ein Diagramm für einen längeren Zeitraum zu betrachten, beispielsweise das Diagramm für 1 Stunde .
Es gibt vier Garbage Collectors, zu denen Sie wechseln können, während Sie die Garbage Collection-Zeiten für Ihre Anwendung beachten:
Seriensammler
Dieser Kollektor verwendet einen einzigen Thread für seine gesamte Garbage Collection. Es ist ideal für Geräte mit einem Prozessor. Es kann jedoch auch auf Multiprozessorgeräten mit kleinen Datensätzen von etwa 100 MB verwendet werden. Sie können es mit der Option -XX:+UseSerialGC aktivieren .
Parallelkollektor
Im Gegensatz zum seriellen Kollektor verwendet der parallele Kollektor mehrere Threads, um die Speicherbereinigung zu beschleunigen. Dieser Kollektor eignet sich für mittelgroße bis große Datensätze für Multiprozessorgeräte.
Sie können diesen Kollektor mithilfe der Option -XX:+UseParallelGC festlegen .
G1 Garbage Collector
Dieser Kollektor ist größtenteils gleichzeitig und eignet sich für Multiprozessorsysteme mit großem Speicherplatz. Sie können es mit der Option -XX:+UseG1GC festlegen .
Z Müllsammler
Der Z-Kollektor ist für Anwendungen mit geringer Latenz konzipiert , die möglicherweise sehr große Heap-Größen haben (möglicherweise sogar in Terabyte). Es führt seine Aktivitäten gleichzeitig aus, ohne einen Anwendungsthread länger als 10 ms anzuhalten. Sie können den Z-Kollektor mit der Option -XX:+UseZGC aktivieren .
5. Threads
Jeder JVM-Thread verfügt über einen Stapel im nativen Speicher. Der Stack speichert verschiedene Thread-Daten wie zum Beispiel lokale Variablen. Sie können die Thread-Stapelgröße mit der Option -Xss festlegen .
Die Standardgröße des Thread-Stacks ist plattformabhängig, beträgt jedoch normalerweise etwa 1 MB.
Wenn die festgelegte Thread-Stapelgröße geringer ist als die für die Berechnung erforderliche Größe, weist Ihr Programm einen StackOverflowError auf .
Beachten Sie, dass die Thread-Stapelgröße mit der Ausführung Ihres Programms zunehmen kann. Wenn die Thread-Stapelgröße zunimmt und nicht genügend Speicher vorhanden ist, tritt bei Ihrem Programm ein OutOfMemoryError auf .
Sie können in Ihrem FusionReactor-Dashboard ( Ressourcen >Threads ) überwachen, wie Threads Speicher nutzen . Auf der Registerkarte „Stack Trace All“ können Sie verschiedene Informationen zu Threads abrufen, einschließlich des zugewiesenen Speichers :
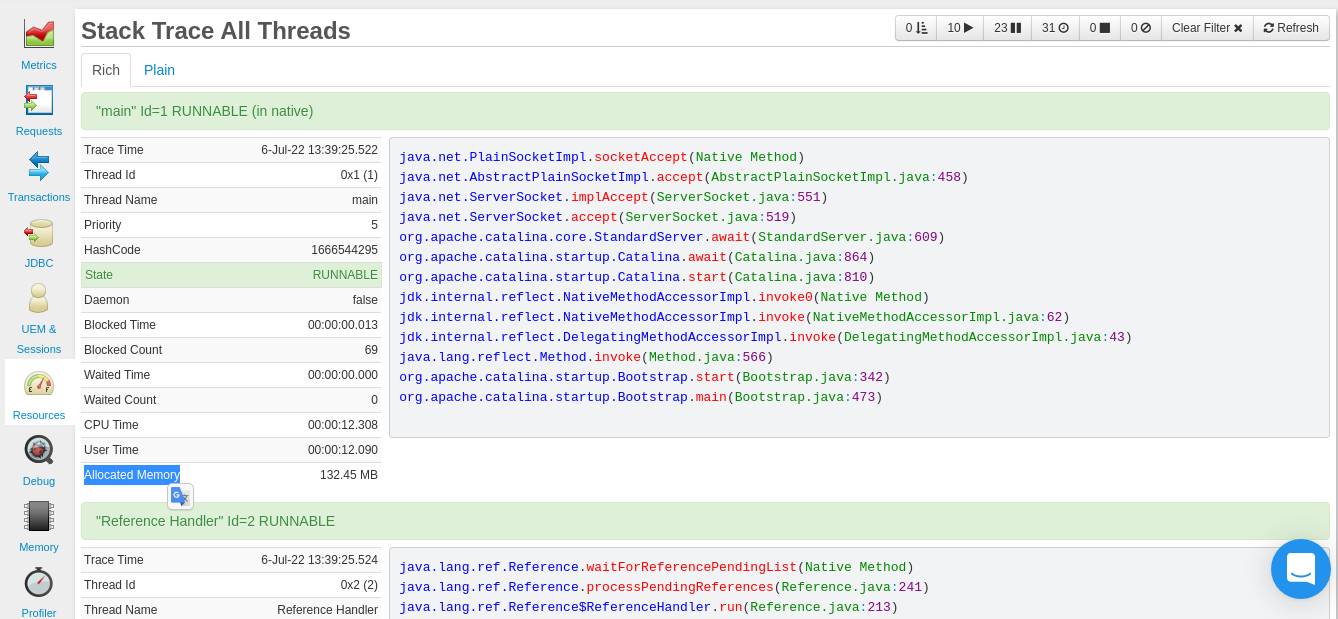
Ziel ist es, nach Threads Ausschau zu halten, die Hunderte von MB Speicher (oder GB) verbrauchen. Sie können dann eine Vorgehensweise auswählen, z. B. einen Thread anhalten, der viel Speicher verbraucht, und ihn dann debuggen.
Im Dashboard „Ressourcen“ > „Threads“ können Sie auf die Schaltfläche „Thread anhalten“ klicken .
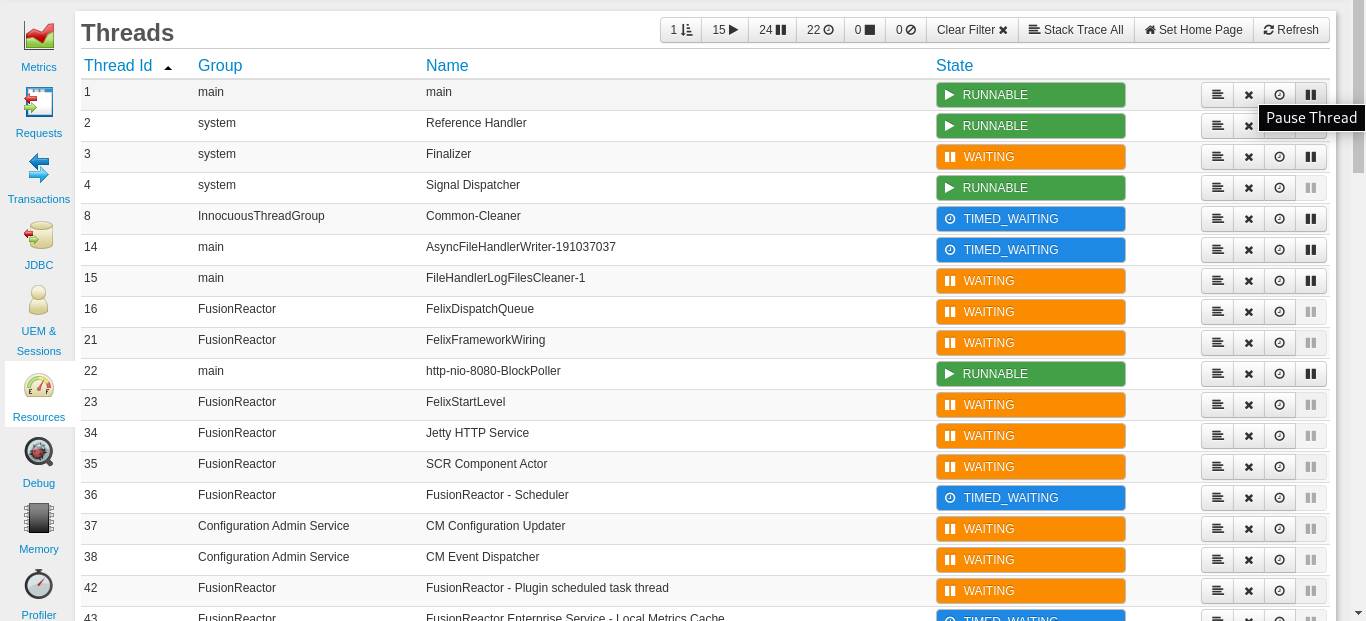
Nach dem Debuggen können Sie auf die Schaltfläche „Fortsetzen“ (neben der Schaltfläche „Neue Überwachung “) klicken, um die Ausführung des zuvor angehaltenen Threads fortzusetzen.
Fazit – So überwachen Sie Nicht-Heap-Speicher
In diesem Artikel wurden Ihnen die verschiedenen Tools gezeigt, die FusionReactor zur Überwachung und Verwaltung von Nicht-Heap-Speicher (nativem Speicher) bietet.








