
What is parsing?
Parsing is a very important process when handling logs because it lets users filter logs in useful ways. Unstructured logs can easily be shared into attribute (key/value) pairs, which helps to create improved alerts and charts.
There is a rise in variable patterns from a lot of complex log lines. However, using the Parse Regex operator will allow users familiar with the regular expression syntax to filter and extract data such as nested fields.
In this article, we are going to discuss the basics of regex, and how to parse variable patterns using Regex.
Basics of Regex
Regex, which stands for regular expression, is a mathematical concept that can be applied to a variety of scientific expressions, especially programming and log management. Most importantly, it is a very important concept when parsing variable patterns within log lines.
Regular expressions are patterns composed of character combinations in strings. An example of a simple characters and combination of simple and special characters are /abc/ and /ab*c/ or /Chapter (\d+)\.\d*/ respectively. The example for simple and special characters includes parenthesis, which can serve as a memory device. Hence, the match made with this pattern will be remembered for future use.
The Parse Regex operator, which is also called the extract operator, allows users who are familiar with regex syntax to easily filter and extract complex data from logs, such as extracting valuable data from nested fields. So the extracted fields can be described by starting and ending with alphanumeric characters and underscore such as (“_”).
| parse regex "<start_expression>(?<field_name><field_expression>)<stop_expression>" | parse regex "<start_expression>(?<field_name><field_expression>)<stop_expression>" [nodrop] | parse regex [field=<field_name>] "<start_expression>(?<field_name><field_expression>)<stop_expression>"
Another term to use is “extract”
| extract "<start_expression>(?<field_name><field_expression>)<stop_expression>"
Options
field=<field_name>
The field=fieldname option provides users the ability to specify a field to parse, which is different from the default message.
nodrop
The nodrop option instructs extracted log results to also include messages that don’t match any segment of the parsed term.
multi
Multiple values carried within a single log message can be parsed with the multi option.
Rules of Regex
To properly parse variable patterns using Regex, certain rules must be followed to ensure the process is correct.
- All regular expressions must be enclosed within quotes, and also a valid JAVA or RE2 expression.
- Only case-sensitive characters can be matched. Hence, no variables are assigned when text segments cannot be matched.
- Fields should be specified to prevent the usage of the entire incoming message/log.
- Multiple parse expression is possible. However, they will be processed according to how they are specified. Meaning that matching strings begins at the start of the first expression.
- It is possible to express multiple parses with shorthand writing techniques. The expressions will be written with shorthand using comma-separated terms.
- Nested named capture groups are not supported.
- Only regular expressions that carry a minimum of one named capturing group are supported by the parse regex operator. So, regular expressions without a capturing group or unnamed capturing group can not be parsed.
For some reason, users might want to convert their regular expressions into a named capturing group to achieve other goals. This conversion can be done using the following steps:
Enclose every character in parenthesis, and append “?”; a capturing group should follow the “?” and the name enclosed within “<>”.
Let’s look at this example below:
| Normal Regex | Regex with named capturing group |
| \d{3}-[\w]* | (?<regex>\d{3}-[\w]*) |
Remember our rules; if your regex carries at least one capturing group, which part of it is enclosed within parentheses, then you can carry out these two options:
You can convert it into a non-capturing group. In this scenario, the regex part will not be extracted into the FusionReactor field. Conversion is easily done by appending “?” to the group right after the parentheses.
| Normal Regex | Regex with non-capturing group |
| (abc|\d{3}) | (?:abc|\d{3}) |
A numbered capturing group can be converted to a named capturing group within your regex string. This conversion can be done by appending a “?” and enclosing the name of the capturing group within “<>”. Usually, FusionReactor will generate a field with the same name that is specified in the named capturing group.
| Normal Regex | Regex with named capturing group |
| (abc|\d{3}) | (?<test_group>abc|\d{3}) |
Parsing Examples
Parsing an IP address
Extracting an IP address from complex log lines is one of the easiest processes when using a parse regex similar to:
... | parse regex "(?<ip_address>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})" | ...
Parsing multiple fields in a single query
Remember our rules; parsing multiple fields in one query is possible using regex. For instance, let’s decide to parse username and host information from logs, it should look like this:
... | parse regex "user=(?<user>.*?):" | parse regex "host=(?<msg_host>.*?):" | ...
Situation to use non-capturing groups
A situation may arise when you have to use non-capturing groups (?:regex). Such situations arise if you have multiple possibilities when matching the regular expression. Also, we can use the group syntax to specify alternative strings in a regular expression. Let’s look at the examples below:
Oct 11 18:20:49 host123.example.com 16234563: Oct 11 18:20:49: %SEC-6-IPACCESSLOGP: list 101 denied tcp 10.1.2.3(1234) -> 10.1.2.4(5678), 1 packet Oct 11 18:20:49 host123.example.com 16234564: Oct 11 18:20:49: %SEC-6-IPACCESSLOGP: list 101 accepted tcp 10.1.2.5(4321) -> 10.1.2.6(8765), 1 packet
Extract the “Protocol” with the following query:
| parse regex "list 101 (accepted|denied) (?<protocol>.*?) "
So, this is what you would actually write:
| parse regex "list 101 (?:accepted|denied) (?<protocol>.*?) "
If you need to capture whether it is “denied” or “accepted” into a field, then you can include this in the query:
| parse regex "list 101 (?<status>accepted|denied) (?<protocol>.*?) "
Parse Multi
Asides from parsing a field value, there is an option for parsing multiple values within a single log message. Hence, the multi-keyword directs the parse regex operator to look across all the values, especially in messages with a varying number of values. The multi-keyword will create copies of each message so that each value can be counted in a field.
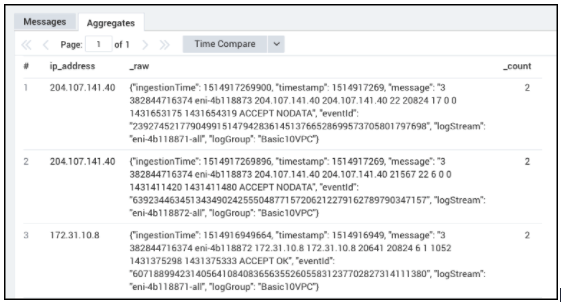
Let’s look at another example of the parse multi regex with Amazon VPC flow logs with the same source and destination IP addresses:
_sourceCategory=aws/vpc
| parse regex "(?<ip_address>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})" multi
| count by ip_address, _raw
| where _count >1
The result/output
Parsing Case insensitive Regex syntax
The Parse regex operator can use case insensitivity by inputting a regex parameter of (?i). For instance, let’s look at the following log:
Line1: The following exception was reported: error in log Line2: The following exception was reported: Error in log Line3: The following exception was reported: ERROR in log
The (?i) informs the parser to ignore case insensitivity for the following expression. So, the “error” in the case sensitive log can be matched with the following parse regex expression.
| parse regex "reported:\s(?<exception>(?i)error)\s"
The outcome should look like this in the following parsed fields:
| Exception | Message |
| ERROR | Line3: The following exception was reported: ERROR in log |
| Error | Line2: The following exception was reported: Error in log |
| error | Line1: The following exception was reported: error in log |
Summary How to Parse Variable Patterns using Regex
If you are into programming, and you are using the Parse regex operator, then your software will run faster because a simple regex engine is likely to outperform a top-notch plain text operator. Whether you are trying to parse case-sensitive variable patterns, multiple values, or non-capturing groups, using the Parse Regex operator can improve the entire process.








